 Instrumental variable estimation of truncated local average treatment effects
Instrumental variable estimation of truncated local average treatment effects
PLoS ONE


Competing Interests: The authors have declared that no competing interests exist.

- Altmetric
Instrumental variable (IV) analysis is used to address unmeasured confounding when comparing two nonrandomized treatment groups. The local average treatment effect (LATE) is a causal estimand that can be identified by an IV. The LATE approach is appealing because its identification relies on weaker assumptions than those in other IV approaches requiring a homogeneous treatment effect assumption. If the instrument is confounded by some covariates, then one can use a weighting estimator, for which the outcome and treatment are weighted by instrumental propensity scores. The weighting estimator for the LATE has a large variance when the IV is weak and the target population, i.e., the compliers, is relatively small. We propose a truncated LATE that can be estimated more reliably than the regular LATE in the presence of a weak IV. In our approach, subjects who contribute substantially to the weak IV are identified by their probabilities of being compliers, and they are removed based on a pre-specified threshold. We discuss interpretation of the proposed estimand and related inference method. Simulation and real data experiments demonstrate that the proposed truncated LATE can be estimated more precisely than the standard LATE.
Introduction
Instrumental variable (IV) analysis can be used to address bias from unobserved confounding in non-randomized studies when estimating a treatment effect on an outcome of interest. Many IV methods have been developed based on linear and survival regression models [1–5], however, they require a homogeneous treatment effect assumption to find meaningful causal effects in the framework of the Rubin causal model [6, 7]. This homogeneity assumption may be too strong for application to real observational studies. Imbens and Angrist [8] introduced a causal estimand that can be identified by an IV called the local average treatment effect (LATE). This estimand does not require treatment effects to be homogeneous for all study subjects. The LATE represents the average treatment effect for a group of compliers, who choose their treatment according to the random variation in an IV.
A key assumption for a valid IV is that it is independent of the potential outcomes and treatments. Angrist et al. [9] showed that if this assumption holds without any covariates, then the Wald estimator, the ratio of sample covariances, is consistent for the LATE. Sometimes, IVs are considered to be random only if some covariates are controlled. For example, Brooks et al. [10] controlled for patient’s socioeconomic and clinical characteristics, and nearest hospital distance in their IV analysis, where breast conserving surgery plus irradiation (BCSI) rate was used as an IV to compare BCSI and mastectomy in stage II breast cancer patients. Adjusting for covariates to generate valid IVs is straightforward in IV linear regression models, such as two-stage least squares. However, covariate adjustment in estimation of the LATE requires different approaches. Abadie [11] developed a method to estimate the LATE conditional on observed covariates. This approach requires the estimation of instrumental propensity scores (IPSs), which are analogous to propensity scores (PSs) for the probability of treatment, and the construction of an outcome model for compliers as a function of the treatment and covariates, which is called the local average response function. Weighting and regression methods have been developed to estimate the conditional and marginal LATEs, which address confounded instruments [12, 13]. In this study, we particularly focused on the weighting approach, which only requires the IPSs to be estimated.
In general, PS weighting requires a positivity assumption that the PSs are between 0 and 1. Extreme PSs close to 0 or 1 are problematic because the average treatment effect (ATE) is estimated from a pseudo-population, where each subject has been treated and untreated. Subjects with extreme PSs receive extremely large PS weights to realize the pseudo-population. Extreme PSs result in limited overlap of covariate distributions between comparison groups and make the inverse probability weighting (IPW) estimator unstable. Methods such as truncation and overlap weights have been proposed to deal with this problem. Truncation [14] removes subjects whose PSs are extreme, say below 0.05 or above 0.95. Overlap weights [15] continuously down-weight the subjects with extreme PSs rather than discarding them. Various simulation studies have showed that these methods perform much better than the IPW estimator [16, 17].
Weak IVs are known to amplify the bias of IV estimators and complicate the related asymptotic distributions [18–22]. To deal with weak instruments, we propose a truncation method for the weighting estimator of the LATE. For this, we use the lemma of Abadie [11] that the probabilities of being a complier are greater than 0 for all subjects when the monotonicity assumption of Angrist et al. [9] holds. Therefore, we seek more reliable IV estimation of the weighting estimator for the LATE by truncating the subjects whose probabilities of being a complier are very close to or below zero. The proposed method follows the framework of the truncation method in PS analysis, but it tackles the weak IV problem and related positivity issue that occur when weighting study subjects to identify the population of compliers.
The remainder of this article is organized as follows. We begin with a discussion of the notation and assumptions used for the LATE with a confounded IV. Then, we present the main results for the proposed truncated local average treatment effect (TLATE), which can be estimated more reliably than the LATE when the IV is weak. Based on simulations, we compare the proposed TLATE estimator with the LATE estimator in terms of variance and IV strength. For real-world application, we used the data from a population-based prospecitive cohort study to estimate the effect of a respiratory syncytial virus on lower respiratory tract infections. We end the article with concluding remarks.
Notation and assumptions
To define the LATE, we introduce some notation and assumptions. Let Z ∈ {0, 1} be the binary IV and D(z) ∈ {0, 1} be the binary potential treatment value that would be seen if Z = z. The actual treatment received is defined as D = (1 − Z)D(0) + ZD(1). Let Y(z, d) be the potential outcome that would be seen if Z = z and D = d. Under the assumption of exclusion restriction (Assumption 3 below), Y(z, d) can be written as Y(d). Then, the observed outcome can be expressed as Y = DY(1) + (1 − D)Y(0). Let X be a vector of observed covariates.
Angrist et al. [9] divided the population into four groups in terms of D(0) and D(1): compliers if D(1) > D(0), always-takers if D(1) = D(0) = 1, never-takers if D(1) = D(0) = 0 and defiers if D(1) < D(0). These groups can only be partially identified because only D(0) or D(1) is observed for each subject. Among these four groups, under certain assumptions, causal treatment effects are identifiable only for compliers. Let U denote the latent compliance class, where U = 0 for never-takers, U = 1 for always-takers and U = 2 for compliers. Defiers are removed under the assumption of monotonicity (Assumption 5 below).
Angrist et al. [9] defined the LATE as
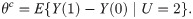
Assumption 1 Independence of the instrument:
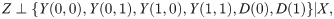
Assumption 2 Positivity: 0 < e(X) < 1.
Assumption 3 Exclusion restriction: Y(0, d) = Y(1, d) for d = {0, 1}.
Assumption 4 Nonzero average causal effect of Z on D: pr{D(1) = 1 ∣ X} > pr{D(0) = 1 ∣ X}.
Assumption 5 Monotonicity: pr{D(1) ≥ D(0) ∣ X} = 1.
Assumption 1 means that Z is as-if randomized once we condition on X. Assumption 2 means that any study subject has a positive probability of being assigned to both instrument groups. Assumption 3 means that variation in Z affects the potential outcomes only through its effect on D. Assumption 4 indicates that Z is positively correlated with D given X. Assumption 5 excludes defiers from the study population. Monotonicity trivially holds when only the participants assigned to a treatment arm have the opportunity to receive the active treatment, as in a single consent design [24].
To estimate the LATE with covariates, one can use the weighting IV estimator presented in equation (11) of Frölich [13]:
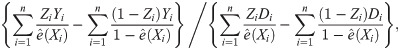
Truncated local average treatment effects
Instead of estimator (1), one may want to use the following normalized estimator:
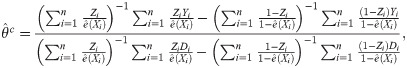
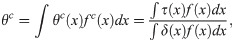
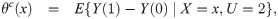
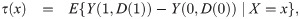
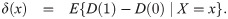
Frölich [13] showed that the semiparametric efficiency bound for θc is proportional to 1/P(U = 2)2. Therefore, if the overall proportion of compliers is close to zero, the regression and weighting estimators for the LATE will have very large variances. Abadie [11] showed in Lemma 2.1 of his paper that under monotonicity, δ(x) is greater than 0, and this positivity assumption implied by monotonicity may be more likely to be violated empirically if P(U = 2) is very close to zero. That is, subjects whose estimated δ(x) values are very close to or below zero considerably contribute to a weak instrument. To overcome the problems regarding a weak instrument, we propose the truncated LATE (TLATE), where subjects whose compliance scores are below a pre-specified threshold value are excluded from the analysis.
The proposed estimand is defined as
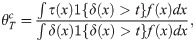
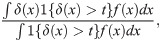
The following theorem addresses the local causal estimand identified by Eq (4).
Theorem 1 Under Assumptions 1-5, can be expressed as
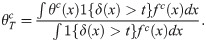
For estimation of the TLATE, following Crump et al. [14], we re-estimate the IPSs for the truncated sample. That is, we select a sample of subjects whose δ(x) values are greater than a pre-specified t. Then, we estimate the IPSs using only this sample and plug the re-estimated IPSs into Eq (2).
To implement our approach, we must estimate δ(x). In a single consent design, δ(Xi) = E(Di ∣ Xi, Zi = 1) = pr(Di = 1 ∣ Xi, Zi = 1). Therefore, we can fit a logistic regression model of D on X to the group Z = 1 and then predict δ(Xi) for all subjects. This procedure makes all estimated δ(Xi) values positive. For a general case, we fit both pr(Di = 1 ∣ Xi, Zi = 1) and pr(Di = 1 ∣ Xi, Zi = 0) using only the Z = 1 and Z = 0 groups with logistic regression models. Then, we predict the values of pr(Di = 1 ∣ Xi, Zi = 1) and pr(Di = 1 ∣ Xi, Zi = 0) for all subjects and take the differences. This does not guarantee that all estimated δ(Xi) values are positive. The proposed method can exclude the subjects with negative compliance scores by choosing t appropriately.
Simulation study
We compared the proposed truncation method with the LATE method by evaluating the absolute percentage bias, standard error, and IV strength of the TLATE and LATE estimates using simulated data sets. We considered one covariate X, which was a standard normal random variate. Using this X, we generated the IV (Z) from the following logistic regression model:
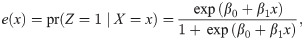
From each simulated data set, we fitted a logistic regression model to estimate the IPSs and calculated the LATE estimate using Eq (2). For the TLATE, we used the 5th to 51st percentiles of the estimated compliance scores for the value of t. While increasing the size of the percentile cutpoint, we used a smaller data set. We fitted logistic regression models of D on X to the Z = 1 and Z = 0 groups separately. Then, we predicted pr(Di = 1 ∣ Xi, Zi = 1) and pr(Di = 1 ∣ Xi, Zi = 0) for all subjects and took the differences as the estimates of the compliance scores.
Figs 1–3 show the simulation results when the overall IV strength was weak, mild, and moderate, i.e., when pr(U = 2) = 0.1, 0.3, and 0.5, respectively. The absolute bias, standard error, and IV strength of the LATE and TLATE estimates are shown as functions of the percentile of the estimated compliance scores for the cutpoint t. The first value of each performance measure was obtained without truncation, i.e., when t was slightly smaller than the 0th percentile. All estimates had less than 5% bias. The bias was reduced as pr(U = 2) increased. In general, as t increased, the standard error decreased and the IV strength increased. Truncation became more beneficial as the association between the covariate and compliance class grew: in general, the slopes for the reduction in the standard error and increment in the IV strength became greater as γ1 increased. The standard error reduced most significantly up to approximately the 10th percentile across the different scenarios of pr(U = 2). When γ1 was 2 or 3, the standard error reduced monotonically up to the 51st percentile. However, when γ1 = 1, the standard error reached a plateau at approximately the 20th percentile in the scenario of pr(U = 2) = 0.3 and at approximately the 10th percentile in the scenario of pr(U = 2) = 0.5.

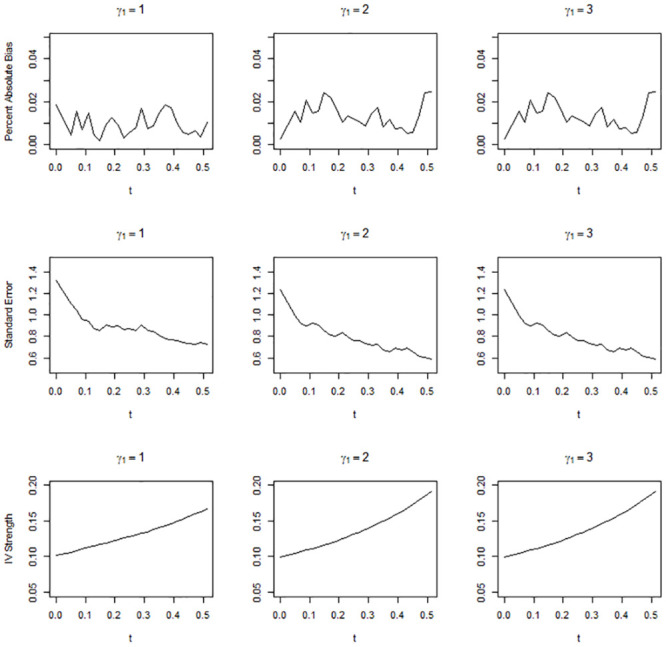
Absolute percentage bias, standard error, and IV strength for the local average treatment effect with a complier population size of 0.1.
The X-axis indicates the percentile of the estimated compliance scores for the cutpoint t.
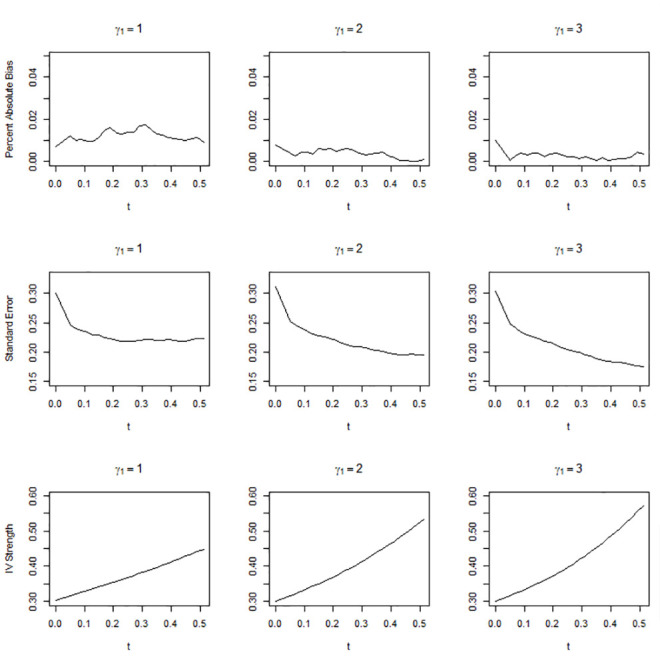
Absolute percentage bias, standard error, and IV strength for the local average treatment effect with a complier population size of 0.3.
The X-axis indicates the percentile of the estimated compliance scores for the cutpoint t.
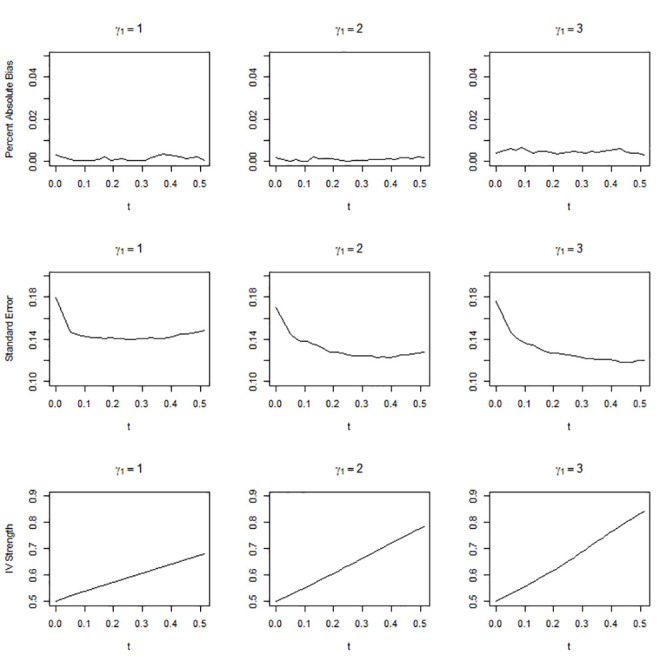
Absolute percentage bias, standard error, and IV strength for the local average treatment effect with a complier population size of 0.5.
The X-axis indicates the percentile of the estimated compliance scores for the cutpoint t.
Application
The PRI.DE study was a population-based prospective cohort study of lower respiratory tract infections (LRTI) in the German population of infants and children aged less than 3 years [25]. Among the 5310 eligible cases of LRTI, Stampf et al. [26] used 3078 complete cases to estimate the marginal odds ratio effect of a respiratory syncytial virus (RSV) on the severity of LRTI. In our study, we used the same data set but estimated the risk difference of severe LRTI.
The outcome was the severity of LRTI, with Y = 1 indicating severe LRTI resulting in hospitalization and Y = 0 indicating non-severe LRTI requiring only a pediatric practitioner. The treatment variable was current RSV infection, with D = 1 indicating the presence of RSV and D = 0 otherwise. Among the 3078 patients, 1803 were hospitalized and 1031 were infected with RSV. The covariates included gender, age, external care, siblings, current breast feeding, parental atopy, preterm delivery, tobacco, congenital heart defect, ethnic group, and region of country.
We used former RSV infection as an IV. We assumed former RSV infection did not directly affect the probability of developing severe LRTI during the current RSV infection, and the covariates were given. Our IV was equal to Z = 0 if the infant had been infected with RSV formerly and Z = 1 if the infant had not. Thus, D(0) was the potential current RSV infection when the infant had been infected formerly, and D(1) was the potential current RSV infection when the infant had not. Thus, compliers were infants who had a current RSV infection if they had not been infected formerly, D(1) = 1, and did not have a current RSV infection if they had been infected formerly, D(0) = 0. Always-takers were infants who had a current RSV infection regardless of former RSV infection. Never-takers were infants who did not have a current RSV infection regardless of former RSV infection. Defiers were infants who had a current RSV infection if they had been infected formerly, D(0) = 1, and did not have a current RSV infection if they had not been infected formerly, D(1) = 0. We assumed that monotonicity held, and thus defiers were excluded from the analysis. Table 1 is a frequency table for former RSV infection (i.e., the IV) and current RSV infection. Among those who had been infected formerly, 20% were not infected, while among those who had not been infected formerly, 34% were infected. Thus, former RSV infection increased the likelihood of current RSV infection. The overall IV strength was approximately 15%. The partial F-test statistic for the proposed IV was 10.62, which is on the boderline of the typical rule of thumb of 10 [19].

| Current RSV infection | ||
|---|---|---|
| Former RSV infection | Not infected (0) | Infected (1) |
| Infected (0) | 126 | 31 |
| Not infected (1) | 1921 | 1000 |
The IPS was defined as the probability of having no former RSV infection. We estimated the IPSs, pr(Z = 1 ∣ X = x), using a logistic regression model with main effects of the covariates. The estimated IPSs ranged from 0.78 to 0.99. We estimated the compliance scores as described before. The estimated compliance scores ranged from −0.45 to 0.61.
Table 2 lists the inference results for the LATE and TLATE at different values of the cutpoint t. The cutpoint value ranged from the 5th to the 25th percentiles of the estimated compliance scores, and the actual values of the 5th and 25th percentiles were −0.177 and 0.029, respectively. We estimated the standard error and 95% confidence interval of the point estimate using bootstrapping: for each casual estimate, we obtained 1000 bootstrap replications, calculated the sample standard error of them, and took their 2.5th and 97.5th percentiles. The LATE estimate was 0.004, and the TLATE estimates were from 0.051 to 0.079. For the purpose of comparison, we estimated the ATE, which was 0.077 with a standard error of 0.017. The TLATE at the 25th percentile was 0.079, which is similar to the ATE, but it was not significantly different from 0. We defined the relative efficiency as the variance of the LATE estimator divided by that of the estimator under consideration [27]. Following this definition, the relative efficiency of the TLATE at the 25th percentile was 1.84.
| Percentile | Estimate | IV strength | SE | LB | UB |
|---|---|---|---|---|---|
| 0.00 | 0.004 | 0.146 | 0.317 | −0.620 | 0.606 |
| 0.05 | 0.072 | 0.176 | 0.267 | −0.451 | 0.609 |
| 0.10 | 0.074 | 0.173 | 0.268 | −0.441 | 0.665 |
| 0.15 | 0.056 | 0.194 | 0.293 | −0.390 | 0.552 |
| 0.20 | 0.051 | 0.199 | 0.248 | −0.400 | 0.588 |
| 0.25 | 0.079 | 0.205 | 0.233 | −0.355 | 0.582 |
“SE” is the standard error of the LATE or TLATE estimate. “LB” and “UB” are the lower and upper bounds of the 95% confidence interval.
Conclusion
Approaches dealing with the positivity issue with the PSs of treatment have been well developed, including the truncation and overlap weights methods [14, 15]. We proposed an IV estimation of truncated LATEs to deal with the problem of weak instruments and the related positivity violation. The proposed method resembles the truncation approach for PS weighting, but it removes the subjects who are very unlikely to be compliers. Our simulation study showed that the relative efficiency of the proposed TLATE increases as the variation of the compliance score increases. Therefore, our method will be useful for data for which the instruments are weak but the compliance score varies considerably across subjects. In our analysis of PRI.DE data, the estimated compliance score varied considerably across infants, and approximately 20% of the subjects had negative compliance scores. The analysis showed that the TLATE estimates were more precise than the standard LATE estimate.
A main limitation of our approach is to lose a part of the study sample by excluding some subjects based on compliance scores, and thus the LATE can be estimated from a smaller population of compliers. The reduced study sample, however, can represent a population that is more desirable for IV analysis because the subjects who are very unlikely to be compliers are removed. In general, the relative population size of compliers estimated from the reduced sample grows as the cutpoint for compliance scores increases. One interesting measure for IV analysis is the effective sample size of compliers, which can be calculated as the product of the sample size and IV strength. Our analysis of PRI.DE data shows that the relative population size as well as the effective sample size can be increased after truncation. The effective sample size based on the untruncated PRI.DE data is 3078 × 0.146 ≈ 450, while that based on the truncated data at the 25th percentile is 3078 × 0.75 × 0.205 ≈ 474.
We used maximum likelihood to estimate a logistic regression model for the IPSs, but other estimation methods can be used. To reduce the impact of model misspecification in parametric modeling, one can use the covariate balancing PS [28]. One could also use nonparametric methods, such as generalized boosting models in which the tuning parameters are selected to optimize covariate balance [29]. Various comparison studies have shown that these methods, when used for PS weighting or doubly robust estimation, work more favorably than maximum likelihood in various simulation scenarios, but their comparative performances depend on the data generating models for the outcome and treatment [30–33].
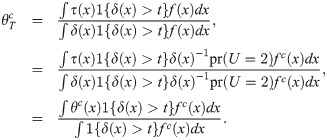
References
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33