
The authors have declared that no competing interests exist.
Immune repertoires provide a unique fingerprint reflecting the immune history of individuals, with potential applications in precision medicine. However, the question of how personal that information is and how it can be used to identify individuals has not been explored. Here, we show that individuals can be uniquely identified from repertoires of just a few thousands lymphocytes. We present “Immprint,” a classifier using an information-theoretic measure of repertoire similarity to distinguish pairs of repertoire samples coming from the same versus different individuals. Using published T-cell receptor repertoires and statistical modeling, we tested its ability to identify individuals with great accuracy, including identical twins, by computing false positive and false negative rates < 10−6 from samples composed of 10,000 T-cells. We verified through longitudinal datasets that the method is robust to acute infections and that the immune fingerprint is stable for at least three years. These results emphasize the private and personal nature of repertoire data.
Immune repertoires are a trove of personal information: unique to each individual, they are also windows into their past and future health. Thanks to their potential for personalized medicine and progress of sequencing technologies, these repertoires are now routinely sequenced. As a consequence they raise the question of identifiability of samples. In this paper, we estimate the quantity of immune cells needed to associate two samples from the same individual: as little as a finger prick worth of blood can serve as an immune fingerprint that can distinguish even identical twins, without giving away genetic information about non-consenting relatives. We show that this fingerprint is stable through time, and is not erased during infections or vaccinations.
Personalized medicine is a frequent promise of next-generation sequencing. These high-throughput and low-cost sequencing technologies hold the potential of tailored treatment for each individual. However, progress comes with privacy concerns. Genome sequences cannot be anonymized: a genetic fingerprint is in itself enough to fully identify an individual, with the rare exception of monozygotic twins. The privacy risks brought by these pseudonymized genomes have been highlighted by multiple studies [1–3], and the approach is now routinely used by law enforcement. Sequencing experiments that focus on a limited number of expressed genes should be less prone to these concerns. However, as we will show, B- and T-cell receptor (BCR and TCR) genes are an exception to this rule.
BCR and TCR are randomly generated through somatic recombination [4], and the fate of each B- or T-cell clone depends on the environment and immune history. The immune T-cell repertoire, defined as the set of TCR expressed in an individual, has been hailed a faithful, personalized medical record, and repertoire sequencing (RepSeq) as a potential tool of choice in personalized medicine [5–9]. In this report, we describe how, from small quantities of blood (blood spot or heel prick), one can extract enough information to uniquely identify an individual, providing an immune fingerprint. The “Immprint” classifier analyzes this immune fingerprint to decide whether two samples were sampled from the same individual.
Given two samples of peripheral blood containing respectively M1 and M2 T-cells, we want to distinguish between two hypothetical scenarios: either the two samples come from the same individual (“autologous” scenario), or they were obtained from two different individuals (“heterologous” scenario), see Fig 1A.

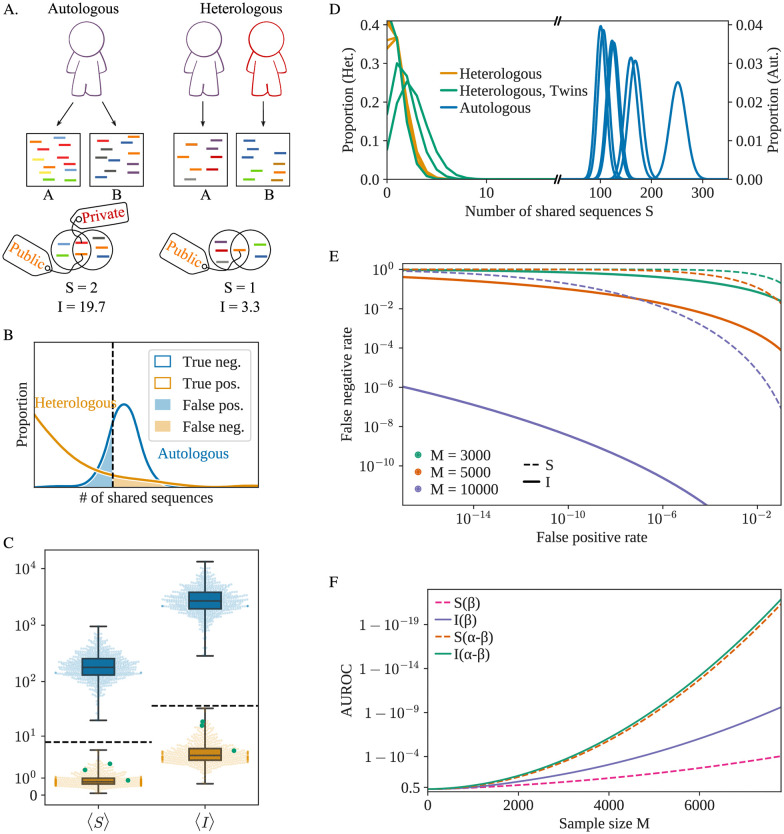
A) The two samples A and B can either originate from the same individual (autologous) or two different individuals (heterologous). In both scenarios, sequences can be shared between the two samples, but their quantity and quality vary. B) Schematic representation of the distribution of the or scores for multiple pairs of samples extracted from the same individual (in the autologous scenario) or the same pair of individuals (heterologous). The dashed vertical line represents the threshold value. C) Expected value of and for different pairs of samples, sampled from the same individual (in blue) or different ones (yellow). Green dots represent samples extracted from pairs of identical twins. The dashed lines represents the theoretical upper bound for heterologous repertoires (see Methods) for both and (γ = 12). D) Sampling distributions of for 6 different patients (autologous case, each blue curve is one patient) or 6 different pairs of patients (heterologous, each yellow or green curve is a pair of patients) for M = 5000. The y-axis scale on the left is adapted to the heterologous distributions while the scale on the right corresponds to the (much wider) autologous ones. The 3 sampling distributions in green correspond to a pair of samples extracted from identical twins. E) Detection Error Trade-off (DET) graph for both summary statistics and different sample sizes . (γ = 12) outperforms in all scenarios. F) AUROC (Area Under Receiver Operating Characteristic), as a function of M. The AUROC is a traditional measure of the quality of a binary classifier (a score closer to one indicates a better classifier). The results are shown for and both in the default case (only the β chain considered) or for the full (α—β) receptor.
TCR are formed by two protein chains α and β. They each present a region of high somatic variability, labeled CDR3α and CDR3β, randomly generated during the recombination process. These regions are coded by short sequences (around 50 nucleotides), which are captured by RepSeq experiments. The two chains are usually not sequenced together so that the pairing information between α and β is lost. Most experiments focus on the β chain, and when not otherwise specified, the term “receptor sequence” in this paper will refer only to the nucleotide sequence of the TRB gene coding for this β chain (which include CDR3β). Similarly, as most cells expressing the same beta chain are clonally related, we will be using the terms “clone” and “clonotype” to refer to set of cells with the same nucleotide TRB sequence, even if they were produced in separate generation events and are not real biological clones (since we have no means of distinguishing the two cases). CDR3β sequences are very diverse, with more than 1040 possible sequences [10]. For comparison, the TCRβ repertoire of a given individual is composed of 108 to 1010 unique clonotypes [11, 12]. As a result, most of the sequences found in a repertoire are “private”.
To discriminate between the autologous and heterologous scenarios, one can simply count the number of unique nucleotide receptor sequences shared between the two samples, which we call . Samples coming from the same individual should have more receptors in common because T-cells are organized in clones of cells carrying the same TCR. By contrast, should be low in pairs of samples from different individuals, in which sharing is due to rare convergent recombinations. Appropriately setting a threshold to jointly minimize the rates of false positives and false negatives (Fig 1B), we can use as a classifier to distinguish autologous from heterologous samples. is not normalized for sequencing depth and values of should not be compared between samples of different size.
The score can be improved upon by exploiting the fact that some receptors are much more likely than others to be generated during V(D)J-recombination, with variations in generation probability (Pgen, [13–15]) spanning 15 orders of magnitude. Public sequences (with high Pgen) are likely to be found in multiple individuals [16], while rare sequences (low Pgen) are unlikely to be shared by different individuals, and thus provide strong evidence for the autologous scenario when found in both samples. To account for this information, we define the score:
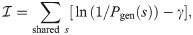
We tested the classifiers based on the and scores on TCRβ RepSeq datasets from 656 individuals [17]—labeled according to their cytomegalovirus (CMV) serological status. Sequences were downsampled to mimic experiments where M1 = M2 = M cells were sampled and their receptors sequenced. The frequency of a particular clonotype in the sample (the proportion of cells expressing a particular beta chain) was estimated using the read counts of unique TCRβ sequences, and the mean values of and computed with a procedure designed to correct for the limited diversity of the sampled repertoire relative to the full repertoire, see Methods 4.3. Similar results may be obtained when M1 and M2 are different (see Methods). The clones most often shared between two autologous samples are also the most clonally expanded—and hence are probably antigen experienced. We verified that the sequence statistics of those expanded clonotypes did not differ from generic ones (S1 Fig).
In Fig 1C, we plot the mean value of (over many draws of M = 5000 cells) for each individual (autologous scenario, in blue) and between pairs of different individuals (heterologous scenario, in yellow). The two scenarios are clearly discernable under both scores. This result holds for pairs of monozygotic twins obtained from a distinct dataset [18] (green dots), consistent with previous reports that twins differ almost as much in their repertoires as unrelated individuals [18–20]. Heterologous scores (yellow dots) vary little, and may be bounded from above by a theoretical prediction (dashed line) based on a model of recombination [21] (see Methods). On the other hand, autologous scores (blue dots) show several orders of magnitude of variability across individuals. These variations stem from the clonal structure of the repertoire, and correlate with measures of diversity (S2 Fig), which is known to vary a lot between individuals and correlates with age [22], serological status, and infectious disease history [23, 24]. To explore the worst case scenario of discriminability, hereafter we will focus on the individual with the lowest autologous found in the dataset.
The sampling process introduces an additional source of variability within each individual. Two samples of blood from the same individual do not contain the exact same receptors, and the values of and is expected to vary between replicates. Examples of these variations are shown in Fig 1D. The blue (respectively yellow) curves correspond to the sample distributions in the autologous (heterologous) scenario for different individuals (pairs of individuals). The distribution of is well-approximated by a Poisson distribution, while follows approximately a compound distribution of a normal and Poisson distributions (see Methods for details). Armed with these statistical models of variations, we can predict upper bounds for the false negative and false positive rates. As seen from the detection error trade-off (DET) graph Fig 1E, the Immprint classifier performs very well for a few thousand receptors with an advantage for .
With 10, 000 cells, corresponding to ∼10 μL of blood, Immprint may simultaneously achieve a false positive rate of < 10−16 and false negative rate of < 10−6, allowing for the near-certain identification of an individual based on the score in pairwise comparisons against the world population ∼1010. When a large reference repertoire has been collected (M1 = 1, 000, 000, corresponding to ∼1mL of blood), an individual can be identified with just 100 cells (S3 Fig).
The AUROC estimator (Area Under the Curve of the Receiver Operating Characteristic), a typical measure of a binary classifier performance, can be used to score the quality of the classifier with a number between 0.5 (chance) and 1 (perfect classification). The score outperforms the score (Fig 1F), particularly above moderate sample sizes (M ≈ 5000). Both scores can be readily generalized to the case of paired receptors, if the pairing of the two chains is available through single-cell sequencing [25–27] or computational pairing [28], we can consider the sequence of the full receptor TCRαβ, instead of just TCRβ. The generation probability of the full TCR is then given by Pgen(α, β) = Pgen(α) × Pgen(β)[29]. Because coincidental sharing of both chains is substantially rarer than with the β chain alone, using the paired chain information greatly improves the classifier.
While this paper focuses on T-cells and TCR sequences, the structure of the B-cell receptors (BCR) repertoire is very similar to the TCR repertoire and we expect to find qualitatively similar results. As an example we use the dataset obtained in Ref. [30] to measure and for IGH chains (forming half of the BCR receptor), S4 Fig. We see that 5000 IgG+ memory B-cells are enough to reliably identify the individuals in the study. However, B-cells are 5 times less common in peripheral blood than T-cells, and somatic hypermutation tends to distort the statistics of receptors, reducing the reliability of our classifier. Hence, for practical applications, T-cells are better means of identification.
The previous results used samples obtained at the same time. However, immune repertoires are not static: interaction with pathogens and natural aging modify their composition. The evolution of clonal frequencies will decrease Immprint’s reliability with time, especially if the individual has experienced immune challenges in the meantime.
To study the effect of short-term infections, we analyzed an experiment where 6 individuals were vaccinated with the yellow fever vaccine, which is regarded as a good model of acute infection, and their immune system was monitored regularly through blood draws [18]. We observe an only moderate drop in caused by vaccination (Fig 2A).
![A) Evolution of I (M = 5000) during vaccination, between a sample taken at day 0 (vaccination date) and at a later timepoint. Each color represents a different individual. Each pair timepoint/individual has two biological replicates. The dashed line represents the threshold value. B) Evolution of I between a sample taken at year 0 and a later timepoint. The red histogram corresponds to one of the individuals sampled in [18] and the blue curves show theoretical estimates, fitted to match (τ = 0.66). C) Evolution of the (normalized) mean of I (M = 5000) as a function of time for different values of the turnover rate τ. The dashed line represents the threshold value divided by the smallest value of It = 0 (M = 5000) in the data. The data points were obtained from the datasets [35] (yellow), [18] (green) and [22] (orange). Different markers indicate different individuals.](/dataresources/secured/content-1765798879194-50b8c284-5f2a-4070-9b1b-28f554f98eab/assets/pgen.1009301.g002.jpg)
A) Evolution of (M = 5000) during vaccination, between a sample taken at day 0 (vaccination date) and at a later timepoint. Each color represents a different individual. Each pair timepoint/individual has two biological replicates. The dashed line represents the threshold value. B) Evolution of between a sample taken at year 0 and a later timepoint. The red histogram corresponds to one of the individuals sampled in [18] and the blue curves show theoretical estimates, fitted to match (τ = 0.66). C) Evolution of the (normalized) mean of (M = 5000) as a function of time for different values of the turnover rate τ. The dashed line represents the threshold value divided by the smallest value of t = 0 (M = 5000) in the data. The data points were obtained from the datasets [35] (yellow), [18] (green) and [22] (orange). Different markers indicate different individuals.
This is consistent with the fact that infections lead to the strong expansion of only a limited number of clones, while the rest of the immune system stays stable [31–34]. While other types of infections, auto-immune diseases, and cancers may affect Immprint in more substantial ways, our result suggests that it is relatively robust to changes in condition.
We then asked how stable Immprint is over long times. Using longitudinal datasets [18, 22, 35], we show in Fig 2 that the Immprint score is only slightly reduced for samples collected at intervals of up to three years. For longer timescale, given the lack of longitudinal datasets, we turn to mathematical models [12, 36–39] to describe the dynamics of the repertoire. Following the model of fluctuating growth rate described in Ref. [38], we define two typical evolutionary timescales for the immune system: τ, the typical turnover rate of T-cell clones, and θ, which represents the typical time for a clonotype to grow or shrink by a factor two as its growth rate fluctuates. The model predicts a power-law distribution for the clone-size distribution, with exponent −1 − τ/2θ. This exponent has been experimentally measured to be ≈ − 2 [10], which leaves us with a single parameter τ, and θ = τ/2. An example of simulated evolution of Immprint with time is shown in Fig 2B The highlighted histogram represents a data point at two years obtained from [18]. While a fit is possible for this specific individual (τ = 0.66 in Fig 2B), the τ parameter is not universal, and we expect it to vary between individuals, especially as a function of age. In Fig 2C we explore the effect on the stability of Immprint for a range of reasonable values for the clone turn-over rate τ, from 6 months to 10 years, encompassing both previous estimates of the parameter [38] and measured turnover rates for different types of T-cells [40]. While Fig 2 focuses on , the behaviour is similar for (see S5 Fig). We observe that under this model, for most individuals and bar exceptional events, Immprint should conserve its accuracy for years or even decades.
In summary, the T-cells present in small blood samples provide a somatic and long-lived barcode of human individuality, which is robust to immune challenges and stable over time. While the uniqueness of the repertoire was a well known fact, we demonstrated that the most common T-cells clones are still diverse enough to uniquely define an individual and frequent enough to be reliably sampled multiple times. Unlike genome sequencing, repertoire sequencing can discriminate monozygotic twins with the same accuracy as unrelated individuals. Additionally, a person’s unique immune fingerprint can be completely wiped out by a hematopoietic stem cell transplant [41].
A potential complication in applying Immprint is the convergent evolution of repertoires: individuals who encounter similar pathogenic environments could share many receptors. While this phenomenon occurs [17, 42], its influence on the immune repertoire is low. For example, in the context of cytomegalovirus infection, shared TCR clones are only slightly more common in co-infected individuals [17], and the result of Immprint does not seem to be affected (S6 Fig). The possibility to discriminate between twins—who shared a common environment for part of their lives—also hints that in most cases the effects of environment-driven convergence is small. Nonetheless we cannot reject the possibility that this effect is stronger for some specific pathogens, or long and strongly overlapping infection histories with pathogens that severely modify immune repertoires. A limit case study to quantitatively investigate this effect would require looking at data from mice living in otherwise sterile environments that are exposed in a controlled way to the same pathogens at the same time, bearing in mind that the diversity of mice repertoires is smaller than that of humans.
The different datasets used cover a range of different sequencing methods (see 4.1), but different approaches may lead to slightly different threshold choices. In particular, in practical implementations, sequencing depth is an important concern. One needs enough coverage to sequence TCRβ genes from as many as possible of the T-cells present in the sample, in order to measure a more precise immune fingerprint. In addition, the specific calculations presented here only apply to peripheral blood cells. Specific cell types or cells extracted from tissue samples may have different clonal distributions and potentially different receptor statistics. For example the value of in the autologous case varies between CD4+ and CD8+ T-cells (S7 Fig), although different individuals remain distinguishable using each subset.
Immprint is implemented in a python package and webapp (see Methods) allowing the user to determine the autologous or heterologous origin of a pair of repertoires. Beyond identifying individuals, the tool could be used to check for contamination or labelling errors between samples containing TCR information. The repertoire information used by Immprint can be garnered not only from RepSeq experiments, but also from RNA-Seq experiments, which contain thousands of immune receptor transcripts [43, 44]. Relatively small samples of immune repertoires are enough to uniquely identify an individual even among twins, with potential forensics applications. At the same time, unlike genetic data from genomic or mRNA sequencing, Immprint provides no information about kin relationships, very much like classical fingerprints, and avoids privacy concerns about disclosing genetic information shared with non consenting relatives.
We use five independant RepSeq datasets in this study: (i) genomic DNA from Peripheral blood mononuclear cells (PBMCs) from 656 healthy donors [17]; (ii) cDNA of PBMCs sampled from three pairs of twins, before and after a yellow-fever vaccination [18]; (iii), (iv) two longitudinal studies of healthy adults [22, 35];(v) cDNA dataset of IGH genes (B-cells) from 9 individuals, with multiple replicates [30].
CDR3 nucleotide sequences were extracted with MIGEC [45] (for the second dataset) coupled with MiXCR [46]. We also extract the frequency of reads from the three datasets. The non-productive sequences were discarded (out-of-frame, non-functional V gene, or presence of a stop codon). The generation probability (Pgen) was computed using OLGA [47], with the default TCRβ model. The frequency of each clone was estimated by summing the frequencies of all reads that shared the same nucleotide CDR3 sequence and identical V,J genes.
The preprocessing code is distributed on the Git repository associated with the paper. We also developed a command-line tool (https://github.com/statbiophys/immprint) that discriminates between sample origins, and a companion webapp (https://immprint.herokuapp.com).
To discriminate between the autologous and heterologous scenarios, we introduce a log-likelihood ratio test between the two possibilities:
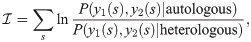
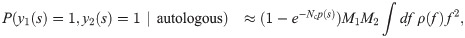
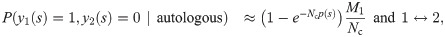
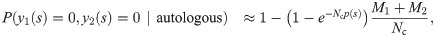
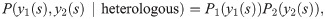
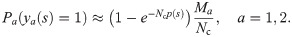
Since only the term y1(s) = y2(s) = 1 (shared sequences) is different between the autologous and heterologous cases, we obtain:
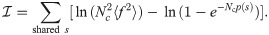
Further assuming Nc p(s) ≪ 1, and p(s) = Pgen(s)q−1 (where q accounts for selection [21] and Pgen(s) is the probability of sequence generation [14]), the score simplifies to Eq 1, with γ = −ln(qNc〈f2〉) = ln(q−1〈f〉/〈f2〉). The factor γ depends on unknown parameters of the model, but can be estimated assuming a power-law for the clone size distribution [48], ρ(f)∝ f−2 extending from f = 10−11 to f = 0.01, and q = 0.01 [21], yielding γ ≈ 12.24. Alternatively we optimized γ to minimize the AUROC, yielding γ ≈ 15 (S9 Fig). Since performance degrades quickly for larger values, we conservatively set γ = 12.
The sampling of M cells from blood is simulated using large repertoire datasets. In a bulk repertoire sequencing dataset, the absolute number of cells for each clonotype (cells with a specific receptor) is unknown, but the fraction of each clonotype can be estimated using the proportion of reads that are associated with this specific receptor. To estimate the autologous and of two samples of size M1 and M2 in the absence of true replicates, we computed their expected values from a single dataset containing N reads, from which two random subsamples of sizes M1 and M2 were taken. The mean value of is equal to , where f(s) is the true (and unknown) frequency of sequence s. A naive estimate of 〈mS〉 may be obtained by repeatly resampling subsets of sizes M1 and M2 from the observed repertoire, calculate for each draw, and average. One get the same result by replacing f(s) by in the previous formula, where n(s) is the number of s reads in the full dataset, and N = ∑s n(s). However, this naive estimate leads to a systematic overestimate of the sharing (visible when compared with biological replicates, see S10 Fig), simply because this procedure overestimates the probability of resampling rare sequences, in particular singletons whose true frequency may be much lower that 1/N. A similar bias occurs when computing . To correct for this bias, we look for a function h(n) that satisfies for all f:
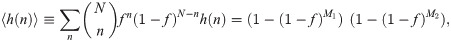
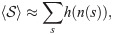
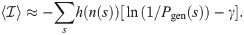
Expanding the right-hand side of Eq 9 into 4 terms, we find that satisfies Eq 9 provided that:
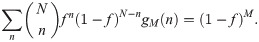
Under the change of variable x = f/(1−f), the expression becomes:
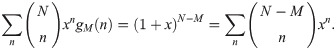
Identifying the polynomial coefficients in xn on both sides yields:
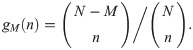
These corrected estimates agree with the direct estimates using biological replicates (S10 Fig).
Similarly, and in heterologous samples can be estimated using:
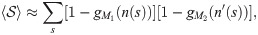
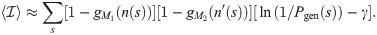
When the two samples were extracted from two different individuals (heterologous scenario), we can use the universality of the recombination process to give upper bounds on the values of and . These bounds are represented by the dashed lines in Fig 1C). If two samples of respectively M1 and M2 cells, containing T1 ≤ M1 and T2 ≤ M2 unique sequences are extracted from two different individuals, the number of shared sequences between them is given by [21]:
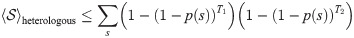
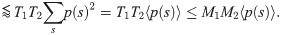
p(s) is the probability of finding a sequence s in the blood. Following [21], we make the approximation p(s) = Pgen(s)q−1, where the q = 0.01 factor is the probability that a generated sequence passes selection. Then 〈p(s)〉 can be estimated from the mean over generated sequences. Similarly, we can estimate as
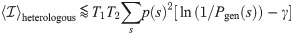
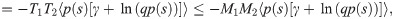
To make the quantitative predictions shown in Fig 1, we need to constrain the tail behavior of the distributions of and , for the two scenarios.
The statistic can be rewritten as a sum of Bernouilli variables over all possible sequences, each with a parameter corresponding to its probability of being present in both samples, either in the autologous or the heterologous case. Therefore is a Poisson binomial distribution, a sum of independent Bernouilli variables with potentially different parameters. The variance and tails of that distribution are bounded by those of the Poisson distribution with the same mean, denoted by ma for the autologous case, and mh for the heterologous case (S11 Fig).
Thanks to that inequality, the rates of false negatives and false positives for a given threshold r are bounded by:
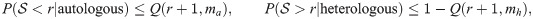
Similarly, can be viewed as a sum of independent random variables, all following the distribution of ln(1/Pgen)−γ. However, this distribution differs in the two scenarios. Sequences shared between more than one donor have an higher probability of being generated, their ln(Pgen) distribution has higher mean and smaller variance (S12 Fig).
The sum is composed of a relatively large number of variables in most realistic scenarios. Hence, we rely on the central limit theorem to approximate it by a normal distribution, of mean and variance proportional to . Explicitly:
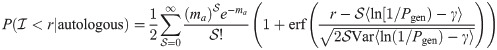
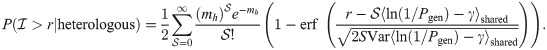
The AUROC are computed based on these estimates, by numerically integrating the true positive rate with respect to the false negative rate as the threshold r is varied.
We use the model of Ref. [38] to describe the dynamics of individual T-cell clone frequencies f under a fluctuating growth rate reflecting the changing state of the environment and the random nature of immune stimuli:
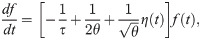
With the change of variable x = ln(f), these dynamics simplify to a simple Brownian motion in log-frequency: ∂t x = −τ−1+ θ−1/2 η(t). In that equation, τ appears as the decay rate of the frequency, while θ is the timescale of the noise, interpreted as the typical time it takes for the frequency to rise or fall by a logarithmic unit owing to fluctuations. Considering a large population of clones, each with their independent frequency evolving according to Eq 24, and a source term at small f corresponding to thymic exports, one can show that the steady-state probability density function of f follows a power-law [38], ρ(f) ∝ f−α, with exponent α = 1+ 2θ/τ. α was empirically found to be ≈2 in a wide variety of immune repertoires [10, 48–50], implying 2θ ≈ τ. The turn-over time τ is unknown, and was varied from 0.5 years to 10 years in the simulations.
We simulated the evolution of human TRB repertoires by starting with the empirical values of the frequencies of each observed clones, from the analysed datasets. A sample of size M was randomly selected with respect to these frequencies, and the frequencies of the clones captured in that sample were then evolved with a time-step of 2 days using Euler-Maruyama’s method, which is exact in the case of Brownian motion. Clones with frequencies falling below 10−11 (corresponding to a single cell in the organism) were removed. At each time t > 0, we measured the mean value of with the formula ∑s(1 − (1 − f(s, t))M) where the sum runs over the sequences captured in the initial sample.
The authors are grateful for the help of Natanael Spisak with the analysis of BCR repertoire datasets.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
 Immune fingerprinting through repertoire similarity
Immune fingerprinting through repertoire similarity
 Facebook
Facebook
 Twitter
Twitter
 Linkedin
Linkedin
 Whatsapp
Whatsapp

