 Human microbiome privacy risks associated with summary statistics
Human microbiome privacy risks associated with summary statistics
PLoS ONE


Competing Interests: The author has declared that no competing interests exist.

- Altmetric
Recognizing that microbial community composition within the human microbiome is associated with the physiological state of the host has sparked a large number of human microbiome association studies (HMAS). With the increasing size of publicly available HMAS data, the privacy risk is also increasing because HMAS metadata could contain sensitive private information. I demonstrate that a simple test statistic based on the taxonomic profiles of an individual’s microbiome along with summary statistics of HMAS data can reveal the membership of the individual’s microbiome in an HMAS sample. In particular, species-level taxonomic data obtained from small-scale HMAS can be highly vulnerable to privacy risk. Minimal guidelines for HMAS data privacy are suggested, and an assessment of HMAS privacy risk using the simulation method proposed is recommended at the time of study design.
Introduction
Humans have coevolved with an immense number of diverse microorganisms that inhabit our bodies, collectively referred to as the human microbiome [1]. Together with the development of metagenomics, recognizing that microbial community composition within the microbiome is associated with the physiological state of the host has sparked a large number of human microbiome association studies (HMAS), which are also referred to as human metagenome-wide association studies (MWAS) [2] in analogy to genome-wide association studies (GWAS) [3]. As in the field of GWAS [4–7], the privacy risk is increasing with the increasing size of publicly available HMAS data.
The privacy threats of HMAS data are based on the fact that individual microbiomes harbor personally identifiable information in the form of microbial community composition. Several prominent studies demonstrated that individual identity can be revealed using the human microbiome. Fierer et al. [8] showed that an individual who touched an object (e.g., computer keyboard) could be identified by matching the compositional profile of the microbiome on the surface of the object to that of the individual’s skin microbiome. While the authors’ approach can be properly applied to forensic analyses, similar microbiome-based approaches can also be used to reveal an individual’s location or intimate partner as shown by Lax et al. [9] and Kort et al. [10]. Besides, Franzosa et al. [11] presented the possibility of a different type of privacy threat that uses information stored in databases; the authors showed that metagenomic codes, as sets of differentiable features of any given microbiome, can be used to identify individuals in the Human Microbiome Project dataset.
Although the development of biological as well as computational/statistical tools for analyzing individual microbiomes helps us to better understand human microbiomes, such tools can be viewed as double-edged swords. The more a tool has resolving power, the more privacy risks confront people as described above. Unfortunately, we might not be able to prevent privacy threats by attackers who utilize microbiome-based forensic techniques because the attackers only need to seize microbiomes from victims. On the other hand, privacy threats by data breaches can be prevented when the HMAS community develops privacy-preserving methods for HMAS data analysis as shown by Wagner et al. [12] and by storing HMAS data in access-controlled databases such as the dbGaP [13], which is currently used as a secure database of human-related genotypic and phenotypic data. However, there is another type of privacy threat that can be caused by the publication of HMAS data. Although raw or detailed data are not presented, summary statistics (e.g., mean frequencies of prokaryotic taxa in study microbiomes) are frequently provided in tables and figures contained in HMAS-based papers. Concerns over privacy breaches due to publishing summary statistics was first raised by Homer et al. [14] with respect to GWAS privacy, and this type of privacy attack was later termed ’attribute disclosure attacks under the summary statistic scenario’ by Erlich and Narayanan [15]. To my knowledge, there have been no reports evaluating the privacy risk of HMAS summary statistics, which led me to perform a simple, foundational study in order to urge the HMAS community to be aware of privacy risks associated with HMAS dataset summary statistics.
In this paper, I demonstrate that the membership of an individual in the samples of an HMAS (e.g., case group or control group) can be revealed easily in the summary statistics of taxonomic compositions calculated from the microbiomes of the samples. Using a simple test statistic that was calculated from binary (presence/absence) taxonomic profiles, my simulation studies showed that publication of species-level taxonomic data obtained from small-scale HMAS can be highly vulnerable to privacy risk. This study asserts that the taxonomic profiles of the human microbiome should be treated as sensitive biometric information in that the HMAS metadata could contain the behavioral history of individuals in addition to medical conditions. I propose minimal guidelines for HMAS privacy and suggest that researchers use the simple simulation presented here to assess the privacy risk at the time of study design with the acknowledgment that a more advanced method could have greater resolving power for privacy breach.
Methods
Development of the test statistic
Suppose two samples R and C, each with size nR and nC, were drawn independently from population of human microbiomes. In HMAS, these samples may correspond to the sets of microbiomes of volunteers in the reference group () and case group (), respectively; each microbiome is a vector of which the elements represent relative frequencies of j = 1,2,⋯,t, where t is the number of operational taxonomic units (OTUs) at different taxonomic levels from phylum to strain and S∈{R, C}. The summary statistics are vectors and , of which the elements are the mean frequencies rj and cj of the OTUs in the pooled data obtained from R and C, respectively. Now consider the microbiome of an individual q, , of which the elements are simple binary measures of presence/absence of OUT j (i.e., ), and suppose we want to determine whether is a member of R or C using and . First, calculate a distance d for OUT j using the absolute difference between and cj and the absolute difference between and rj as follows:
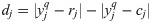
Assuming that OTUs are independent and invoking the central limit theorem for the large number of OTUs (t>50) examined in the HMAS, z-score of dj across all OTUs will follow the standard normal distribution, N(0, 1).
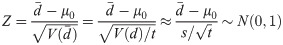
Since the t = max(tR, tC, ty) is large, the variance of d can be estimated reliably by the sample variance s2. The test statistic Z was inspired by Homer et al. [14] and Braun et al. [16]. The authors used a similar test statistic calculated from the single nucleotide polymorphism (SNP) genotyping data to identify an individual’s genotype in GWAS samples. I modified the original test statistic in order to use the binary taxonomic data in HMAS. Because an individual microbiome randomly drawn from population should be equally distant from R and C, μ0 was presumably expected to be zero, i.e., N(0, 1) was a putative null distribution. Thus, under the null hypothesis is a random draw from ), the alternative hypothesis is a member of R) or is a member of C) can be tested with an appropriate significance level α. For example, Z>1.65 rejects H0 in favor of HC at α = 0.05 (one-tailed test).
Distribution simulations
I examined the feasibility of the test statistic Z in identifying the presence of an individual’s microbiome in an HMAS sample with simulated datasets. Suppose that the OTUs correspond to species-level affiliations of microorganisms. Then, the presence of species j in is a Bernoulli random variable with parameter pj. To model the probability distribution of pj , I used four different Beta(π1, π2) distributions. For with a small number of high-frequency species, π1 = 0.1 and π2 = 1.0 were assumed, and for with a large number of high-frequency species, π1 = 1.0 and π2 = 0.1 were assumed. For with a high number of high-frequency species as well as a high number of low-frequency species, π1 = 0.1 and π2 = 0.1 were assumed, which might be more realistic than the above two distributions in that the high-frequency species may correspond to constitutional or autochthonous prokaryotic populations and the low-frequency species may correspond to opportunistic or heterochthonous prokaryotic populations across individual microbiomes. In addition, a Beta(1, 1) (uniform) distribution was also used, which represents our ignorance of the distribution of pj according to the principle of indifference.
Because the individual microbiome in R or C is a set of t random draws of yj~Bernoulli(pj), i.e., , the summary statistics for samples R and C were simulated using and , respectively. To construct density curves of true positives for samples R and C, random draws of and from samples R and C were used to calculate the test statistics ZR+ and ZC+ , respectively. Density curves were estimated using the Gaussian kernel density estimator. To construct density curves of the true null distribution, random draws of from were used to calculate test statistics ZP . Python code for the simulation is available at https://colab.research.google.com/drive/1dOZi8OSo5qHmF7JPyGAP1I_BQdBVSSiC?usp=sharing.
Results and discussion
Overview of simulation results
A simulation study was started with the number of OTUs t =2,000, which roughly reflects the number of species (including uncultivated candidate species) in the human gut microbiome [17], and with nR = nC = 10, which could correspond to small-scale HWAS, under the assumption that pj follows uniform distribution (Fig 1). The null distribution estimated using ZP was very close to N(0, 1) and crisply separated from the distributions of true positives (ZR+ and ZC+), indicating the feasibility of the microbiome-based identification. The distributions of true positives moved toward the null distribution with increasing n or with decreasing t but moved away from the null distribution with decreasing n or with increasing t. Similar distribution patterns were observed for all the underlying distributions of pj assumed (S1–S3 Figs).

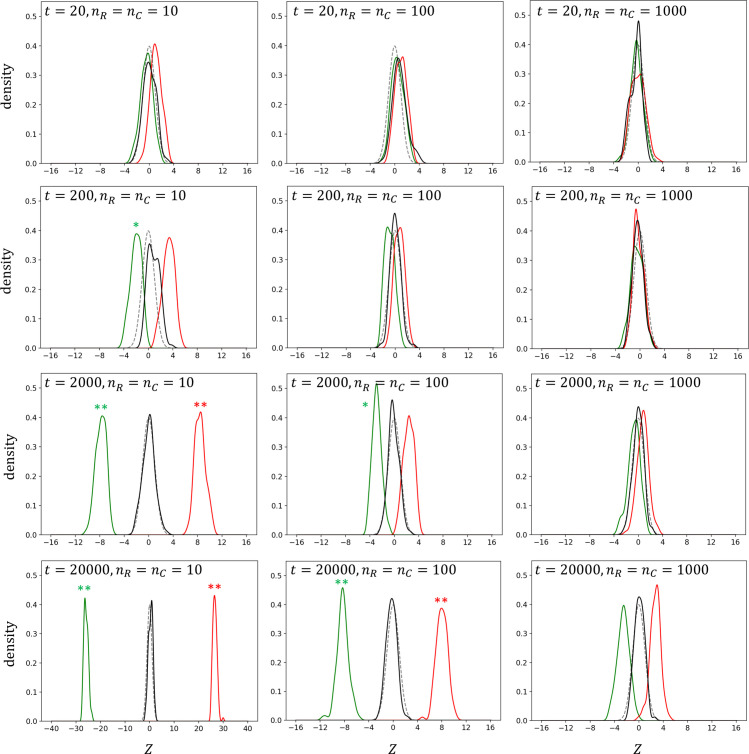
Distributions of the test statistic Z under the assumption that the population OTU frequencies follow a uniform (Beta(1, 1)) distribution.
Density curves for true positives of samples R (ZR+) and C (ZC+) are denoted by green and red lines, respectively. Density curves of simulated null distribution and standard normal distribution are denoted by black and gray lines, respectively. Single and double asterisks represent type II error probabilities β<0.05 and β<0.01, respectively.
For numerical interpretation of the simulation results, I focused on the probability of type II error at α = 0.05 (βR = P(ZR+>zα|HR) or (βC = P(ZC+<zα|HC); the probability that the test statistic is not in the H0 rejection range, given that the alternative hypothesis is true). The power of the test (1−β) is important to a privacy attacker because it would be especially difficult for the attacker with a high β to determine whether the individual under investigation belongs to a particular HMAS sample due to the high false negative rate. α level critical values were obtained from percentiles of ZP distribution because the true null distribution might diverge from N(0, 1). As expected in the density curves, β was far less than 0.01 for the experiments with a large t or small n (S1–S4 Tables).
To formulate the guidelines for human microbiome privacy, the initial simulation study was expanded for virtual HMAS samples with nR = nC = 10, 20,…,100,…,1000 and with t = 20, 30,…,100,…,1000,…,20000. The method was in general slightly more powerful for pj under the uniform distribution (Fig 2) than for pj under other beta distributions (S4 and S5 Figs). In the resulting contour plots, the yellowish area represents higher β (i.e., lower test power); thus, the HMAS samples located in the dark blue area are considered to be vulnerable to privacy risk. The power of the test decreased notably with increasing HMAS sample size (n) or with a decreasing number of OTUs (t) from which the HMAS summary statistics are calculated, and it is possible to notice a borderline where β decreases considerably, which could help in assessing the privacy risk of the HMAS data.
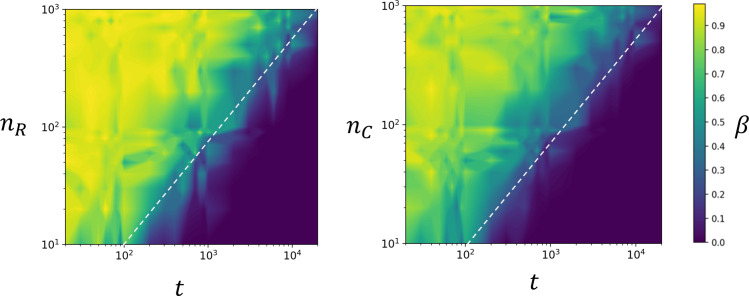
Contour plot representations of the type II error probabilities (β) for true positives of samples R and C under the assumption that the population OTU frequencies follow a uniform (Beta(1, 1)) distribution.
Sample size and the number of OTUs are log-scaled. Dotted line denotes suggested minimal guidelines for HMAS privacy.
Effect of sample size
Samples of a large size approximate the population because or (hence, ), and the distribution of ZR+ or ZC+ would overlap with the null distribution as shown in the selected density curves, indicating that a large sample size will make the classifying method ineffective. Contrarily, for the samples of a small size, significantly deviates from μ0 even if the difference between rj and pj or between cj and pj is very small. Note that the sample size does not increase with the number of technical replicates used in HMAS data, since the sample points in technical replicates are not independent.
For an unequal sample size (e.g., nR = 1,000 and nC = 10), the samples with a larger size would approximate the null distribution, but the test power for identifying a microbiome in a sample with a smaller size would not be affected (S6 Fig). Considering that taxonomic profiles of individual microbiomes in the case sample could be more homogeneous than those in the control sample, the effective size of the case sample might be smaller than the census size of the case sample. This would result in much higher statistical power for testing whether an individual is a member of the case sample, which is a primary interest of the attackers.
Effect of the number of OTUs
With the sample size fixed, an increased number of OTUs would increase the test power. This situation can happen when the HMAS data contains taxonomic profiles with a resolution finer than species level. Under the arbitrary speculation that each species is comprised of ca. 10 strains (t = 20,000), the method was very powerful (β≪0.01) even for a moderate sample size. This is because the denominator of the test statistic shrinks by increasing t compared to the sample mean , which results in a large ZR+ or ZC+. In the same vein, a reduced number (e.g., t = 20) of OTUs (roughly corresponding to near phylum-level) would decrease the power of the test.
Effect of correlation among OTUs
The occurrence of many OTUs in the human microbiome could be correlated, since the microbiome itself is an ecological community [18]. If the correlation among OTUs is significant, the violation of the assumption that OTUs are independent could change the test power. I analytically evaluated the effect of the OUT correlation on test power. If OTUs are not independent, the variance of includes covariance (Cov) terms as follows:
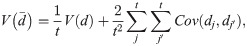
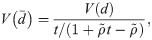
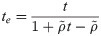
Note that te = t if , 1≤te<t if , and t<te if (te→∞ as ). For example, if three of 10 OTUs show a strong positive correlation, two of these OTUs cannot contribute to the number of OTUs as equally as other independent OTUs. Thus, the effect of a positive could be similar to the effect of a decreased number of OTUs, resulting in decreased test power as in the case of linkage disequilibrium among SNPs [16]. However, can also be negative if negative interactions among OTUs are more prevalent than positive interactions among OTUs, which could subsequently increase test power. Even very small negative correlations (e.g., ) among a moderate number of OTUs (t = 1000) would increase te to 106, while very small positive correlations (e.g., ) decrease te to 500. The negative correlation overwhelmingly affects te because te is a reciprocal function of when t is fixed (S7 Fig). Nonetheless, because cannot be measured from summary statistics unless provided or assumed, the effect of should be investigated more comprehensively in the future.
Additional considerations
I used the binary vector as a query microbiome because it was considered that the binary data is less prone to experimental variations. If a frequency vector is used, the could increase because small differences between and || can accumulate across a large number of OTUs. However, it would not always result in a larger ZR+ or ZC+ because the increased sample variance could counteract the increase in . Thus, the use of a frequency vector might not guarantee more test power, rather it could make more prone to errors in OTU frequencies.
It was assumed that R and C were samples drawn independently from the population of human microbiomes (). Violation of this assumption could shift the location of the null distribution (μ0). Suppose that populations underlying samples R and C (denoted by and , respectively) are all different from the population underlying . If the systemic difference between and is significant, the difference between summary statistics can deviate from zero, i.e., E(Δ) = E(r−c)≠0. Let be the distance metric that includes Δ term as follows:
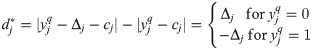
Then, according Braun et al. [16] and using and , the expected value of the distance metric under the null hypothesis is as follows:
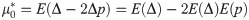
Because −1≤E(Δ)≤1 and ranges from -1 to 1 which is quite small compared to the distance between the distributions of ZP and ZR+ or between the distributions of ZP and ZC+ in the cases where the test power is very high (e.g., t≥2000 and n = 10 or t≥20000 and n = 100) (Fig 1). Moreover, as E(p) deviates from its two extreme values (0 or 1) which are highly unrealistic in microbiome composition, the 2E(Δ)E(p) term counteracts the deviation of from zero (i.e., as E(p)→0.5). Thus, I considered that the violation of the assumption that underlying populations are all different would not alter the main results of this study. In fact, if R (reference/control group) and C (case/treatment group) are assumed to be samples drawn from and , respectively, the test statistic would become very similar to that used for a two-tailed z-test (or t-test) which can be used to test the null hypothesis that is not a member of C.
Although it might be virtually impossible for the HMAS community to develop an almighty shield that protects data against all possible privacy breaching methods, we do not need to overreact to HMAS privacy concerns since the taxonomic profile of the individual’s microbiome could not be a permanent identifier, while a subset of an individual’s microbiome may endure for most of the lifetime. Nonetheless, the HMAS community should have guidelines for reducing the privacy risk, which could be kept minimal in order not to obstruct our understanding of the human microbiome.
Concluding remarks
This study showed the possibilities of privacy breaches using the summary statistics drawn from HMAS data. The key finding was that the publication of species composition data obtained from small-scale HMAS (e.g., t≈1,000 and nR = nC = 10) easily exposes the privacy of the victims. The HMAS samples with moderate size (nR = nC≈100) and t≈1000 were on the vicinity of the borderline. I suggest these figures as a basis for HMAS data release policy while acknowledging a sophisticated test statistic that employs better distance metric along with the violation of underlying assumptions could improve the power of the privacy breaching methods. I propose minimal guidelines for HMAS data release as follows: i) increase the sample size as much as manageable, ii) do not publish species composition data even in the form of summary statistics if the sample size is less than 10, iii) avoid publishing subspecies- or strain-level data unless the sample size is far larger than 100. I also suggest that HMAS researchers evaluate the privacy risk at the time of study design using the simulation method presented in this study. Because the test statistic used was relatively robust against the variations in the models for the distribution of pj, HMAS researchers can simply use uniform distribution and their intended t, nR, and nC to estimate the ‘minimal’ power of the privacy-breaching method.
This study focused only on attribute disclosure attacks under the summary statistic scenario [15]. However, HMAS data privacy concerns are not limited to summary statistics; privacy breaches can occur in various manners at any stage of HMAS data management as described by Wagner et al. [12]. Thus, it is timely that the HMAS community begins comprehensive discussions on HMAS data privacy risks and developing privacy-preserving algorithms for data storage and release.
Acknowledgements
I thank the anonymous reviewers for their helpful comments and suggestions.
References
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18