 Efficient sparse estimation on interval-censored data with approximated L0 norm: Application to child mortality
Efficient sparse estimation on interval-censored data with approximated L0 norm: Application to child mortality
PLoS ONE


Competing Interests: The authors have declared that no competing interests exist.

- Altmetric
A novel penalty for the proportional hazards model under the interval-censored failure time data structure is discussed, with which the subject of variable selection is rarely studied. The penalty comes from an idea to approximate some information criterion, e.g., the BIC or AIC, and the core process is to smooth the ℓ0 norm. Compared with usual regularization methods, the proposed approach is free of heavily time-consuming hyperparameter tuning. The efficiency is further improved by fitting the model and selecting variables in one step. To achieve this, sieve likelihood is introduced, which simultaneously estimates the coefficients and baseline cumulative hazards function. Furthermore, it is shown that the three desired properties for penalties, i.e., continuity, sparsity, and unbiasedness, are all guaranteed. Numerical results show that the proposed sparse estimation method is of great accuracy and efficiency. Finally, the method is used on data of Nigerian children and the key factors that have effects on child mortality are found.
Introduction
Interval-censored failure time data, which means the failure time of interest is only known to belong to a period instead of observed directly, is commonly seen in many fields, such as demography, medicine, and ecology. The statistical analysis of this special data structure has attracted much attention since first being addressed by Finkelstein (1986 [1]), and many researchers have developed significant works related to model estimations (Huang 1996 [2]; Zhang et al. 2005 [3], Zeng, Cai, and Shen 2006 [4], Lin and Wang 2010 [5]). Sun (2006 [6]) made a thorough review of research on interval-censored failure time data. Compared with right-censored data, interval-censored data can be more challenging when modeled in two ways. First, interval-censored data can be more complicated, such that sometimes it is a mixture of interval censoring and right censoring. Right censoring can be considered a special form of interval censoring with the right bound extending to infinity. Second, when implementing the proportional hazards model (Cox 1972 [7]) on right-censored data, one can use partial likelihood and does not have to estimate the baseline hazards function simultaneously with the parameters of interest.
Several methods exist that deal with interval-censored failure time data. Tong, Chen, and Sun (2008 [8]) and Goggins and Finkelstein (2000 [9]) developed approaches for interval censoring, but under strict independent assumptions. These approaches are restricted to several models; for example, the former is only applicable to the additive hazards model (Lin and Ying 1994 [10]). In this paper, a sieve maximum likelihood method with Bernstein polynomials is proposed as a general way that can be applied to many semi-parametric survival models. More information is presented below.
Although basic theories on interval-censored data are well established, studies on variable selection under this data structure are very limited. To the best of our knowledge, penalized partial likelihood has been effectively used since it is intuitive to add a penalization term to the likelihood function. Tibshirani (1997 [11]) and Fan and Li(2002 [12]) successfully applied LASSO and SCAD penalties to the proportional hazards model right after they proposed them. Zou (2006 [13]) developed adaptive LASSO (ALASSO) and Zhang and Lu (2007 [14]) used it with partial likelihood. However, penalized partial likelihood is bounded to the analysis of right-censored data. For variable selection on interval-censored failure time data, piecewise constant functions are occasionally used (Wu and Cook 2015 [15]) to represent the baseline hazards model, incorporated with several penalties and the EM algorithm is applied to optimize the likelihood function. Wang et al. (2019 [16]) introduced a Bayesian adaptive lasso penalty for the additive hazards model with Case I interval-censored data, also known as current status data, in which the subjects are only visited once and one only knows whether it has failed at the exact observation time. Zhao (2020 [17]) developed a broken adaptive ridge (BAR) penalized procedure and, with iterations, some parameters finally shrank to zero. The simulation studies show satisfying results, whereas it is still found to be computationally costly due to the heavy optimization procedures and that there are two parameters to tune.
The object of interest in the present paper is another type of covariate selection technique, i.e., best subset selection (BSS). A typical BSS method is to list all the variable subsets, model with each one of them, and use some information criterion, such as AIC (Akaike 1974 [18]) and BIC (Schwarz 1978 [19]) to judge every subset. For a dataset with n0 uncensored samples and p dimensions of parameters, a criterion has the form as:
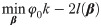
In this study, a form of approximated information criterion is proposed under the interval-censored data structure. The result provides several major contributions to the current literature. First, an approximated BSS method is introduced into the analysis of interval-censored data, with which the variable selection approaches are rarely studied. Second, great efficiency is achieved by conducting the estimation of both the coefficients and baseline hazards function with free-tuning covariate selection simultaneously.
The rest of this paper is organized as follows. In the first section, the notation and detailed estimation procedure of interval-censored data are given. In the next section, the approximation of BSS is presented. In the third section, the simulation results of the proposed method are shown along with several other commonly seen penalties. The application section contains a survey example and the last section concludes this research and addresses a short discussion.
Notation, assumptions, and models
Interval censoring
Consider a failure time study that involves n independent subjects and for an ith subject there is a p-dimensional vector Zi(1 ≤ i ≤ n) that may affect its failure time Ti. According to the proportional hazards model, the cumulative hazard function Λ(t) is given by
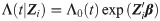
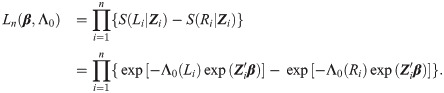
In practice, if one does not observe the failure of some samples during the entire experiment, these samples will be considered right-censored. For right-censored subject, Ri = ∞ and thus S(Ri|Zi) = 0.
To estimate ξ = (β, Λ0), the traditional approach is to maximize the log-likelihood function ln(β, Λ0), usually by finding the zeros of the derivatives. The main difficulty is to estimate finite- and infinite-dimensional parameters at the same time. This problem is discussed in the next section.
Regularized sieve maximum likelihood estimation
To deal with the infinite-parameter estimation problem mentioned above, a sieve method (Huang and Rossini 1997 [23] and Zhou, Hu, and Sun [24]) is developed for our study. Now, consider a parameter space
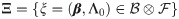
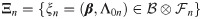
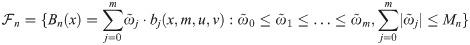
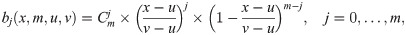
By focusing on sieve space Ξn, the complex estimations of both infinite- and finite-dimensional parameters are converted into a much simpler estimation problem that contains only finite-dimensional parameters (β, ω). Thus, given the argument matrix Z = (Z1, Z2, …, Zn), our likelihood function has the form
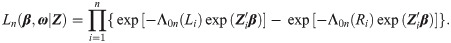
To estimate parameters and select covariates simultaneously, minimizing the sieve log-likelihood function with a penalty term is considered:
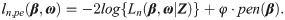
It is intuitive to replace pen(β) with various developed penalties. For LASSO, let ; for SCAD, let with a usually fixed at 3.7; for MCP, let on [0, + ∞]. However, the aforementioned penalties all need a time-consuming tuning process for hyperparameter φ. The approximate information criterion is introduced as a penalty term in the following section, which frees us from tuning the parameter φ and greatly reduces computing time.
Approximated information criterion
Approximation of information criterion
A novel sparse estimation method for interval-censored data is sought from the idea of approximation. The BSS method with certain information criteria does not need the parameter-tuning process, but it is infeasible for a large p. In this part, a smooth approximation of information criteria is developed that can be further used in the way of regularization methods.
The core task is to approximate the ℓ0 norm in the information criteria. The ℓ0 norm can be defined by indicator functions
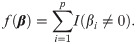
The essential job is to approximate the indicator functions, for which one introduces a function η(x) that satisfies (1) η(0) = 0, (2) η(x) = η(−x), (3) lim|x|→∞ η(x) = 1, and (4) η(⋅); the latter is a smooth function and non-decreasing on . Clearly, η(⋅) has captured the key features of the indicator I(x ≠ 0).
One natural thought is to adopt sigmoid functions, which are commonly used as a smooth output unit in binary classification. The classic choice is the logistic activation sigmoid , and by making some minor changes on the independent variable and the intercept one can successfully develop our solution as follows:
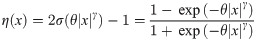

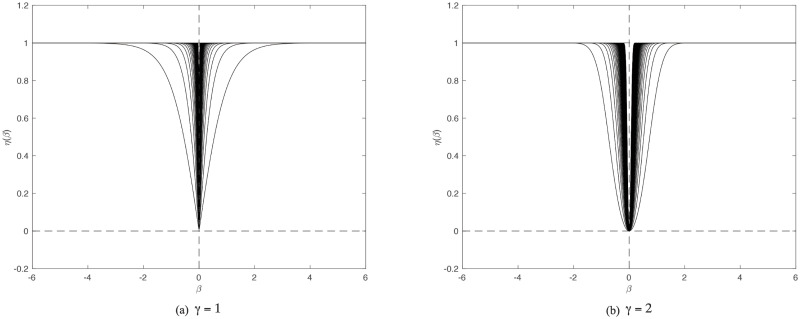
η(⋅) with various values of θ.
Clearly shown is that η(⋅) makes a promising approximation of ℓ0 norm. Note that in both plots the parameter θ varies from 1 to 100 and the curves become sharper with larger θ. (a)γ = 1. (b)γ = 2.
Reparameterization
By introducing η(⋅), the smoothness problem of the ℓ0 norm is preliminarily solved by setting γ = 2. Fan and Li (2001 [28]) proposed three properties that a good penalty should possess: unbiasedness, sparsity, and continuity. Unbiasedness and continuity are apparently ensured by the definition. The sparsity needs to be enforced since we have chose γ = 2. For this purpose, the following reparameterization procedures are considered.
Set a vector and relate ϕ to β by βi = ϕi η(ϕi). Define a matrix
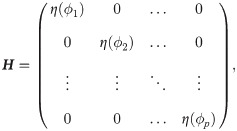
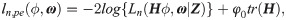
Smoothness. In (4), the second term of the right-hand side ϕ0 tr(H) is smoothed by the definition of η(⋅) when γ = 2, so the problem remaining here is to check the smoothness of the first term, which is essentially decided by H ϕ. β = H ϕ is composed of formula βi = ϕi⋅η(ϕi), i = 1, …, p, and it is commonly known that the product of two smooth functions is also smooth. The relationship of β = H ϕ and ϕ is illustrated in Fig 2, in which a desired one-to-one mapping can be seen.
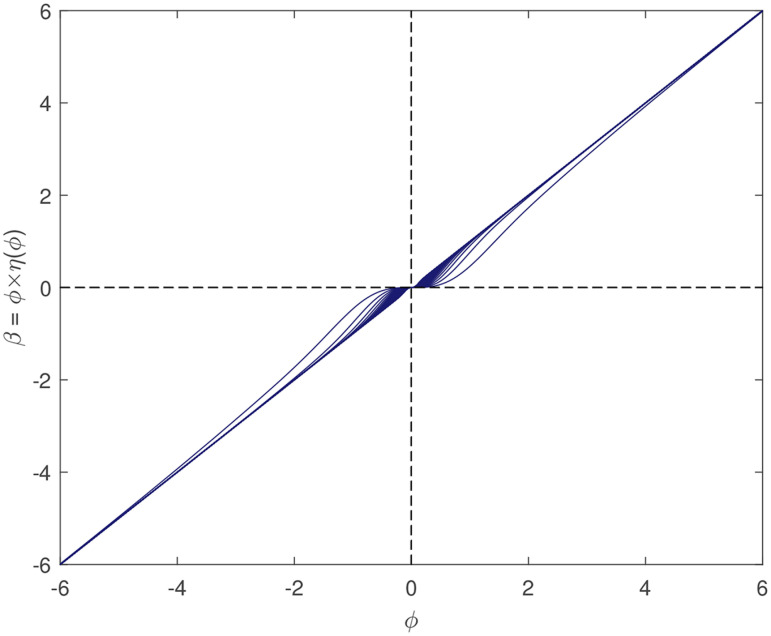
Sparsity. In the preceding section, the reason for choosing γ = 2 was explained, although γ = 1 is favorable in sparsity, which is shown in Fig 1a and 1b. Here, after reparameterization, the relationship between H, which determines the penalty, and β, the true coefficients, is explored. η(ϕ) and β are plotted in Fig 3, which demonstrates that the scale of penalty really assembles the situation when one sets γ = 1, in which the regularization will penalize the likelihood function with a considerably small coefficient allocated to wrong covariates.
Plot of βi and ϕi.
This plot shows desired mutually one-to-one mapping, which is strong evidence supporting reparameterizations. With γ varying from 1 to 100, the function becomes closer to f(ϕ) = ϕ.
Plot of βi and η(ϕi).
This plot displays relationship between true coefficients and penalty term.
One returns to the three properties that Fan and Li recommended, i.e., continuity, sparsity, and unbiasedness, after reparameterizing β with ϕ. Unbiasedness is ensured by the definition of η(⋅). Continuity lies naturally in maintaining smoothness. The goal of sparsity is attained by reparameterization, as explained in this section. Accordingly, the penalty developed herein fulfills all requirements.
Noted that after reparameterization, the penalty term becomes non-convex on β. This implies the penalized log-likelihood function (4) can have multiple local optima and the initial value of optimization process will effect the result. Thus, we use simulated annealing (Belisle 1992 [29]) and BFGS quasi-Newton algorithm (see, e.g., Jorge Nocedal 1980 [30]) to obtain the final result. The simulated annealing is robust and seeks the global optimum, and BFGS algorithm is very fast and assures the result converges to a critical point. Both methods are built-in in Matlab with function simulannealbnd and fminunc. To further scrutinize our method, the numerical results are presented in the next section.
Simulation study
An extensive simulation study is conducted in this section to assess the performance of the proposed sparse estimation method with the approximated information criterion (appIC) on finite interval-censored samples. In this study, a p-dimensional covariate set Zp × n = (Zi, Z2, …, Zp) is considered, and Zi is generated from multivariate normal distribution, with mean zero and covariance matrix Σ. Σ is defined by
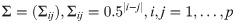
When constructing interval-censored data structure, M visiting points are set in the interval [u, v] with a uniform gap (v − u)/M. To simulate the real situation in which some samples will be difficult to reach, every point is allocated a 50% chance to actually observe a certain sample. In this simulation, u is fixed at 0 and v is set as 3, thus when b0 = 0.5, there are approximately 25% and 35% right-censored portions for Λ0(t) = t and Λ0(t) = log(t + 1), and when b0 = 1, the portions are approximately 30% and 40%. Meanwhile, the number pf observation points M are set at 10 and 20, and the latter is supposed to bring more information.
The hyperparameters of the proposed method are assigned as follows: (1) we set Bernstein polynomials parameter m = 3 because we find it sufficient to characterize the baseline cumulative hazards function; (2) we set γ = 2 for smoothness as described in the previous sections; (3) we fix φ at log(n0) (n0 denotes the number of samples that are not right-censored) as BIC; (4) we assign θ with n0 and the robustness of the estimate with different value of θ is shown in S1 File. The results are presented in Tables 1–5. In Tables 1–4, the performance is measured in three ways: mean, bias and standard deviation (SD), which indicate the accuracy and stability of our estimates. In Table 5, the performance under all scenarios are assessed with four measurements: average selected size (Size), the average true positive size (TP), the average false positive size (TP) and the median and standard deviation of . It can be seen that the bias and standard deviation both greatly reduce when the sample size increases from 100 to 300. When p jumps to 30, appIC method remains feasible and generate good results. And the estimating accuracy and stability generally improve with a more frequent visiting pattern, which is indicated by a large M. Besides, it is shown that the selection correctness of the appIC method increases significantly with greater signals (b0 = 1), compared to b0 = 0.5. Meanwhile, the baseline cumulative hazards function is well modeled by Bernstein polynomials and some of the results are displayed in Fig 4. It is obvious that when n increases, the polynomials fit the hazards function better.

| Mean | Bias | SD | Mean | Bias | SD | |
|---|---|---|---|---|---|---|
| M = 10 | M = 20 | |||||
| n = 100, p = 10 | ||||||
| β1 = 0.5 | 0.537 | 0.037 | 0.243 | 0.537 | 0.037 | 0.233 |
| β2 = 0.5 | 0.494 | -0.006 | 0.270 | 0.486 | -0.014 | 0.249 |
| β9 = 0.5 | 0.519 | 0.019 | 0.267 | 0.509 | 0.009 | 0.250 |
| β10 = 0.5 | 0.501 | 0.001 | 0.251 | 0.509 | 0.009 | 0.215 |
| n = 300, p = 10 | ||||||
| β1 = 0.5 | 0.510 | 0.010 | 0.092 | 0.513 | 0.013 | 0.084 |
| β2 = 0.5 | 0.509 | 0.009 | 0.098 | 0.509 | 0.009 | 0.095 |
| β9 = 0.5 | 0.499 | -0.001 | 0.120 | 0.500 | 0.000 | 0.100 |
| β10 = 0.5 | 0.510 | 0.010 | 0.100 | 0.507 | 0.007 | 0.088 |
| n = 300, p = 30 | ||||||
| β1 = 0.5 | 0.524 | 0.024 | 0.101 | 0.518 | 0.018 | 0.093 |
| β2 = 0.5 | 0.509 | 0.009 | 0.112 | 0.502 | 0.002 | 0.115 |
| β9 = 0.5 | 0.506 | 0.006 | 0.121 | 0.506 | 0.006 | 0.100 |
| β10 = 0.5 | 0.512 | 0.012 | 0.105 | 0.507 | 0.007 | 0.096 |
| Mean | Bias | SD | Mean | Bias | SD | |
|---|---|---|---|---|---|---|
| M = 10 | M = 20 | |||||
| n = 100, p = 10 | ||||||
| β1 = 0.5 | 0.544 | 0.044 | 0.268 | 0.559 | 0.059 | 0.227 |
| β2 = 0.5 | 0.577 | 0.077 | 0.258 | 0.480 | -0.020 | 0.265 |
| β9 = 0.5 | 0.583 | 0.083 | 0.244 | 0.509 | 0.009 | 0.258 |
| β10 = 0.5 | 0.559 | 0.059 | 0.230 | 0.526 | 0.026 | 0.221 |
| n = 300, p = 10 | ||||||
| β1 = 0.5 | 0.518 | 0.018 | 0.093 | 0.519 | 0.019 | 0.091 |
| β2 = 0.5 | 0.513 | 0.013 | 0.111 | 0.515 | 0.015 | 0.108 |
| β9 = 0.5 | 0.504 | 0.004 | 0.119 | 0.506 | 0.006 | 0.109 |
| β10 = 0.5 | 0.520 | 0.020 | 0.102 | 0.514 | 0.014 | 0.095 |
| n = 300, p = 30 | ||||||
| β1 = 0.5 | 0.528 | 0.028 | 0.104 | 0.530 | 0.030 | 0.094 |
| β2 = 0.5 | 0.514 | 0.014 | 0.108 | 0.510 | 0.010 | 0.108 |
| β9 = 0.5 | 0.518 | 0.018 | 0.115 | 0.518 | 0.018 | 0.108 |
| β10 = 0.5 | 0.517 | 0.017 | 0.110 | 0.515 | 0.015 | 0.104 |
| Mean | Bias | SD | Mean | Bias | SD | |
|---|---|---|---|---|---|---|
| M = 10 | M = 20 | |||||
| n = 100, p = 10 | ||||||
| β1 = 1 | 1.152 | 0.152 | 0.276 | 1.132 | 0.132 | 0.251 |
| β2 = 1 | 1.084 | 0.084 | 0.349 | 1.086 | 0.086 | 0.307 |
| β9 = 1 | 1.107 | 0.107 | 0.343 | 1.110 | 0.110 | 0.276 |
| β10 = 1 | 1.118 | 0.118 | 0.282 | 1.105 | 0.105 | 0.253 |
| n = 300, p = 10 | ||||||
| β1 = 1 | 1.039 | 0.039 | 0.129 | 1.036 | 0.036 | 0.119 |
| β2 = 1 | 1.027 | 0.027 | 0.140 | 1.021 | 0.021 | 0.124 |
| β9 = 1 | 1.021 | 0.021 | 0.134 | 1.020 | 0.020 | 0.115 |
| β10 = 1 | 1.035 | 0.035 | 0.136 | 1.028 | 0.028 | 0.122 |
| n = 300, p = 30 | ||||||
| β1 = 1 | 1.065 | 0.065 | 0.138 | 1.048 | 0.048 | 0.119 |
| β2 = 1 | 1.046 | 0.046 | 0.143 | 1.045 | 0.045 | 0.125 |
| β9 = 1 | 1.046 | 0.046 | 0.133 | 1.041 | 0.041 | 0.121 |
| β10 = 1 | 1.050 | 0.050 | 0.145 | 1.037 | 0.037 | 0.127 |
| Mean | Bias | SD | Mean | Bias | SD | |
|---|---|---|---|---|---|---|
| M = 10 | M = 20 | |||||
| n = 100, p = 10 | ||||||
| β1 = 1 | 1.165 | 0.165 | 0.315 | 1.138 | 0.138 | 0.277 |
| β2 = 1 | 1.115 | 0.115 | 0.360 | 1.112 | 0.112 | 0.303 |
| β9 = 1 | 1.155 | 0.155 | 0.355 | 1.143 | 0.143 | 0.314 |
| β10 = 1 | 1.115 | 0.115 | 0.322 | 1.106 | 0.106 | 0.289 |
| n = 300, p = 10 | ||||||
| β1 = 1 | 1.051 | 0.051 | 0.133 | 1.048 | 0.048 | 0.121 |
| β2 = 1 | 1.043 | 0.043 | 0.148 | 1.036 | 0.036 | 0.128 |
| β9 = 1 | 1.033 | 0.033 | 0.138 | 1.038 | 0.038 | 0.132 |
| β10 = 1 | 1.048 | 0.048 | 0.146 | 1.040 | 0.040 | 0.131 |
| n = 300, p = 30 | ||||||
| β1 = 1 | 1.068 | 0.068 | 0.141 | 1.071 | 0.071 | 0.132 |
| β2 = 1 | 1.056 | 0.056 | 0.158 | 1.060 | 0.060 | 0.139 |
| β9 = 1 | 1.060 | 0.060 | 0.158 | 1.057 | 0.057 | 0.135 |
| β10 = 1 | 1.059 | 0.059 | 0.160 | 1.058 | 0.058 | 0.141 |
| Size | TP | FP | MMSE(SD) | Size | TP | FP | MMSE(SD) | |
|---|---|---|---|---|---|---|---|---|
| Λ0(t) = t | Λ0(t) = ln(t + 1) | |||||||
| b0 = 0.5 | ||||||||
| M = 10 | ||||||||
| n = 100, p = 10 | 3.843 | 3.480 | 0.363 | 0.240(0.188) | 3.933 | 3.537 | 0.397 | 0.256(0.186) |
| n = 300, p = 10 | 4.177 | 3.967 | 0.210 | 0.040(0.043) | 4.263 | 3.980 | 0.283 | 0.047(0.047) |
| n = 300, p = 30 | 4.617 | 3.957 | 0.660 | 0.061(0.061) | 4.833 | 3.977 | 0.857 | 0.071(0.061) |
| M = 20 | ||||||||
| n = 100, p = 10 | 3.867 | 3.567 | 0.300 | 0.198(0.162) | 3.950 | 3.570 | 0.380 | 0.218(0.184) |
| n = 300, p = 10 | 4.233 | 3.983 | 0.250 | 0.035(0.034) | 4.210 | 3.983 | 0.227 | 0.042(0.042) |
| n = 300, p = 30 | 4.460 | 3.957 | 0.503 | 0.047(0.047) | 4.717 | 3.977 | 0.740 | 0.062(0.064) |
| b0 = 1 | ||||||||
| M = 10 | ||||||||
| n = 100, p = 10 | 4.357 | 3.940 | 0.417 | 0.449(0.492) | 4.373 | 3.960 | 0.413 | 0.535(0.764) |
| n = 300, p = 10 | 4.267 | 4.000 | 0.267 | 0.077(0.063) | 4.353 | 4.000 | 0.353 | 0.087(0.068) |
| n = 300, p = 30 | 4.943 | 4.000 | 0.943 | 0.089(0.081) | 5.103 | 4.000 | 1.103 | 0.184(0.203) |
| M = 20 | ||||||||
| n = 100, p = 10 | 4.283 | 3.967 | 0.317 | 0.441(0.586) | 4.343 | 3.977 | 0.367 | 0.540(0.915) |
| n = 300, p = 10 | 4.210 | 4.000 | 0.210 | 0.071(0.073) | 4.307 | 4.000 | 0.307 | 0.090(0.080) |
| n = 300, p = 30 | 4.653 | 4.000 | 0.653 | 0.100(0.095) | 4.933 | 4.000 | 0.933 | 0.145(0.134) |
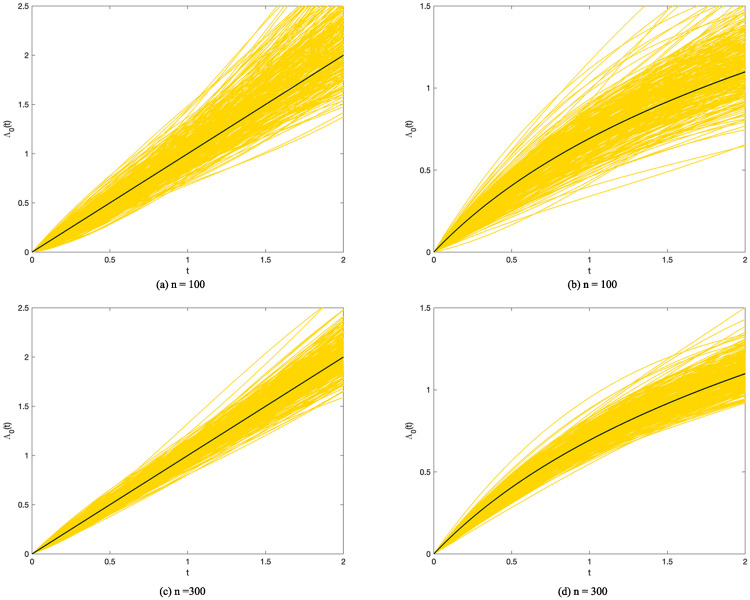
The estimated baseline cumulative functions.
True and simulated baseline cumulative hazards functions shown in black and yellow, respectively. Simulated cumulative hazards function are generated with b0 = 0.5, M = 10 and p = 10. Note here (a)n = 100,Λ0(t) = t. (b)n = 100,Λ0(t) = log(t + 1). (c)n = 300,Λ0(t) = t. (d)n = 300,Λ0(t) = log(t + 1).
To comprehensively assess the performance of appIC, its estimation results were compared with other commonly used approaches to variable selection: LASSO, SCAD, MCP, and BAR under the most serious conditions above, that is M = 10 and b0 = 0.5. The parameters of these penalties are tuned with 5-fold cross validation with the largest log-likelihood value on the validation sets. The estimations with true covariates (oracle) and full models (without selecting the covariates) are presented alongside in Tables 6 and 7. The measurements are described in the previous paragraph. It is obvious that the appIC sparse estimation performs well in both selection correctness and estimation accuracy. The variable size that it has chosen is especially close to the true size, 4, with relatively low FP. That is to say, the proposed method is very unlikely to include an irrelevant variable. Meanwhile, the TP of the appIC method rises to a satisfactory level when n increases from 100 to 300, performing close to SCAD and MCP. Besides, the square error of the proposed method is low with both n = 100 and n = 300. Furthermore, it is worth mentioning that our method is far faster than common penalties owing to the free-tuning on the hyperparameter. The CPU time of different methods under various conditions can be found in S1 File.
| Size | TP | FP | MMSE(SD) | |
|---|---|---|---|---|
| Λ0(t) = t | ||||
| n = 100, p = 10 | ||||
| Full | 10.000 | 4.000 | 6.000 | 0.694(0.814) |
| Oracle | 4.000 | 4.000 | 0.000 | 0.092(0.112) |
| BAR | 4.183 | 3.813 | 0.370 | 0.140(0.152) |
| Lasso | 5.346 | 3.963 | 1.383 | 0.199(0.116) |
| Alasso | 4.384 | 3.707 | 0.677 | 0.211(0.172) |
| SCAD | 4.370 | 3.780 | 0.590 | 0.354(0.168) |
| MCP | 4.200 | 3.613 | 0.587 | 0.208(0.196) |
| appIC | 3.843 | 3.480 | 0.363 | 0.240(0.188) |
| n = 300, p = 10 | ||||
| Full | 10.000 | 4.000 | 6.000 | 0.095(0.096) |
| Oracle | 4.000 | 4.000 | 0.000 | 0.028(0.030) |
| BAR | 4.176 | 4.000 | 0.176 | 0.035(0.029) |
| Lasso | 5.330 | 4.000 | 1.330 | 0.081(0.043) |
| Alasso | 4.406 | 3.993 | 0.413 | 0.061(0.062) |
| SCAD | 4.460 | 3.983 | 0.477 | 0.063(0.051) |
| MCP | 4.393 | 3.993 | 0.400 | 0.031(0.041) |
| appIC | 4.177 | 3.967 | 0.210 | 0.040(0.043) |
| n = 300, p = 30 | ||||
| Full | 10.000 | 4.000 | 6.000 | 0.256(0.211) |
| Oracle | 4.000 | 4.000 | 0.000 | 0.029(0.031) |
| BAR | 4.317 | 4.000 | 0.317 | 0.041(0.032) |
| Lasso | 5.783 | 4.000 | 1.783 | 0.187(0.071) |
| Alasso | 4.756 | 3.943 | 0.813 | 0.141(0.125) |
| SCAD | 4.526 | 3.983 | 0.543 | 0.191(0.081) |
| MCP | 4.540 | 3.963 | 0.577 | 0.033(0.056) |
| appIC | 4.617 | 3.957 | 0.660 | 0.061(0.061) |
Note that Λ0(t) = t.
| Size | TP | FP | MMSE(SD) | |
|---|---|---|---|---|
| Λ0(t) = log(t + 1) | ||||
| n = 100, p = 10 | ||||
| Full | 10.000 | 6.000 | 4.000 | 0.854(1.140) |
| Oracle | 4.000 | 4.000 | 0.000 | 0.090(0.149) |
| BAR | 4.236 | 3.753 | 0.483 | 0.181(0.192) |
| Lasso | 5.476 | 3.943 | 1.533 | 0.204(0.115) |
| Alasso | 4.750 | 3.727 | 1.023 | 0.218(0.151) |
| SCAD | 4.416 | 3.666 | 0.750 | 0.366(0.168) |
| MCP | 4.146 | 3.523 | 0.623 | 0.252(0.290) |
| appIC | 3.933 | 3.537 | 0.397 | 0.256(0.186) |
| n = 300, p = 10 | ||||
| Full | 10.000 | 6.000 | 4.000 | 0.104(0.083) |
| Oracle | 4.000 | 4.000 | 0.000 | 0.033(0.037) |
| BAR | 4.203 | 4.000 | 0.203 | 0.033(0.036) |
| Lasso | 5.253 | 4.000 | 1.253 | 0.070(0.045) |
| Alasso | 4.464 | 3.997 | 0.467 | 0.062(0.063) |
| SCAD | 4.400 | 3.997 | 0.403 | 0.081(0.056) |
| MCP | 4.280 | 3.993 | 0.287 | 0.038(0.285) |
| appIC | 4.263 | 3.980 | 0.283 | 0.047(0.047) |
| n = 300, p = 30 | ||||
| Full | 10.000 | 6.000 | 4.000 | 0.304(0.322) |
| Oracle | 4.000 | 4.000 | 0.000 | 0.028(0.038) |
| BAR | 4.191 | 3.994 | 0.197 | 0.038(0.039) |
| Lasso | 6.333 | 4.000 | 2.333 | 0.131(0.056) |
| Alasso | 4.633 | 3.920 | 0.713 | 0.172(0.162) |
| SCAD | 4.550 | 3.987 | 0.563 | 0.166(0.085) |
| MCP | 4.610 | 3.993 | 0.617 | 0.040(0.057) |
| appIC | 4.833 | 3.977 | 0.857 | 0.071(0.061) |
Note that Λ0(t) = log(t + 1).
Application
In this section, the focus is on Nigerian child mortality data from the Demographic and Health Surveys (DHS) Program (https://www.dhsprogram.com). The dataset records women’s information from various aspects, including their children. The survey was very detailed; nevertheless, due to some practical restrictions the survival time of the children are only recorded in months or years, which makes it an interval-censored data structure. Meanwhile, it is found that the sample child mortality rate is over 20%, significantly higher than the global average, and our goal is to identify the key factors that affects children’s survival status.
A total of 24 potential factors are listed in Table 8. After excluding the samples that hold null value in either one of the variables, 8, 671 valid child samples are found, out of which 6, 830 are right censored. Note that variables 1-14 in Table 8 are dummy variables and are assigned 1 when the corresponding statements are true. Variables 15-24 are standardized so that the significance of all the factors can be compared. Most variables are concerned with the mother, and four variables marked with asterisks in Table 8 are child specific.
| Variable number | Factor | Coefficient |
|---|---|---|
| V1 | De facto place of residence-city | - |
| V2 | De facto place of residence-countryside | - |
| V3 | Has electricity | -0.110 |
| V4 | Has telephone | -1.011 |
| V5 | Presence of soap/ash/other cleansing agent in household | - |
| V6 | Knowledge of ovulatory cycle | - |
| V7 | Ever use of any modern contraception methods | -0.394 |
| V8 | Visited health facilities last 12m | - |
| V9 | Smokes nothing | - |
| V10 | Sex of household head | - |
| V11 | When child is seriously ill, probably can not decide whether to get medical aid | 0.201 |
| V12 | Child is twin* | 1.185 |
| V13 | Sex of child* | - |
| V14 | Proper body mass index | - |
| V15 | Education in single years | - |
| V16 | Number of household members | -0.107 |
| V17 | Number of children 5 and under | - |
| V18 | Number of eligible women in HH | - |
| V19 | Total children ever born | 0.241 |
| V20 | Age of respondent at 1st birth | - |
| V21 | Age at first marriage | - |
| V22 | Ideal number of children (grp) | - |
| V23 | Preceding birth interval* | -0.440 |
| V24 | Mother age of birth* | - |
Note that four variables marked with asterisks are child specific and variables 1-14 are dummy variables, assigned as 1 when corresponding statements are true.
To apply the appIC regression procedure here, m = 3, γ = 2, θ = n0 = 1841, and φ = log(n0) (BIC) are set. Meanwhile, the observation interval on the children is set as [0, 144]; that is to say, if the child lives to 144 months, or 12 years old, he or she is recorded as right censored. The results are shown in Table 8. According to the present research, eight variables have effects on child mortality. Having telephone, longer preceding birth interval of the mother, the usage of modern contraceptive methods, having electricity and more household members can reduce child mortality hazards, in the order of effectiveness. Meanwhile, the hazards increase with the mother having had more children and the child being twin. If the family can not decide whether to get medical aid when the child is seriously ill, the mortality hazards also increase. The baseline cumulative hazards function and baseline survival function are presented in Fig 5.
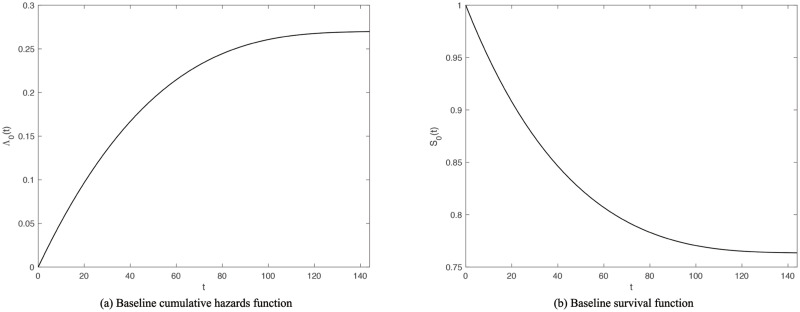
Estimated baseline cumulative hazards function and baseline survival function of children in survey.
Note that t is measured in months. We see that the hazards function curve and survival function curve become flat as children grow up, which is consistent with reality.
Conclusion
In this paper, an approximated information criterion for the proportional hazards model under the interval-censored failure time data structure is discussed. The common penalties usually need a time-consuming hyperparameter tuning process, which is not necessary if one uses BSS with some well-known information criteria, such as BIC or AIC. The modified logistic sigmoid function is used herein to emulate the ℓ0 norm and accordingly convert the BIC as a penalized likelihood function that can be implemented in the way of regularizations. This method literally builds a bridge between BSS and the regularizations, with a special and novel strength in efficiency since it simulates the baseline hazards function, estimates coefficients of covariates, and chooses variables simultaneously, without tuning hyperparameters for the penalty term. The numerical results, including an application to child mortality, show that this method possesses great potential to facilitate mainstream sparse estimation for interval-censored data, with which the subject of variable selection is rarely studied.
There exist some interesting directions of planned future work. First, in this paper only the situation that the censoring time is independent of the failure time is considered, which sometimes may not conform with practice. Many studies discussing informative censoring exist and one can explore the proposed methods under that circumstance. The second direction is to change the survival model. Herein, only the proportional hazards model is applied, but several other superb semi-parameter survival models exist, e.g., the additive hazards model. One can compare the estimation accuracy or efficiency and show the reason. Third, in practice, some datasets with a very large covariate dimension are seen, a typical one of which is genetic data. Study on this problem is absolutely meaningful and clearly more research is needed in this direction.
Acknowledgements
Thanks are due to the Demographic and Health Surveys (DHS) Program for the application data.
References
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30