
Competing Interests: The authors have declared that no competing interests exist.
The two-parameter of exponentiated Gumbel distribution is an important lifetime distribution in survival analysis. This paper investigates the estimation of the parameters of this distribution by using lower records values. The maximum likelihood estimator (MLE) procedure of the parameters is considered, and the Fisher information matrix of the unknown parameters is used to construct asymptotic confidence intervals. Bayes estimator of the parameters and the corresponding credible intervals are obtained by using the Gibbs sampling technique. Two real data set is provided to illustrate the proposed methods.
In engineering applications, a system may be subjected to several stresses such as extreme temperature and pressure. The survival and performance of such systems strongly depend on their resistance strength. The models which try to measure this resistance are called stress-strength models, and in the simplest terms, it can be described as an evaluation of the experienced random “stress” (Y) and the available “strength” (X) which overcomes the stress. This simple explanation induces the definition of the reliability of a system as the probability that the system is strong enough to overcome the stress that it is subjected to. Therefore, the reliability parameter could be defined as R = P(X>Y).
The estimation of the reliability parameter has extensive literature. It has been studied under different assumptions over the distribution of X and Y. [1] studied the ML estimation of R under the assumption that the stress and strength variables follow a bivariate exponential distribution. By considering a multivariate normal distribution, the MLE has been studied by [2]. The estimation of R, when the distribution is Weibull, were considered by [3]. See [4] and references therein for more details, works on the estimation of R and its applications. In some recent works [5], estimated R under the assumption that the stress and strength variables are independent and follow a generalized exponential distribution. [6] considered the estimation of R, when X and Y are independent, and both follow a three parameter Weibull distributions. Some other applications of the stress and strength models in the framework of transportation problems, which were estimated by ML methods, include [7–9]. Other engineer applications of these methods, which were applied in the Bayesian framework, could be found at [10–12].
The only difference in the above-mentioned works was the different distributions which the authors have been chosen for the random quantities. In some situations, one could not obtain the complete data and have to consider certain sampling schemes in order to get incomplete data for X and Y. [13–15] have been studied the problem of making inference on R based on progressively Type II censored data. [16], based on the record data, by considering one parameter generalized exponential distribution, has been studied ML and Bayesian estimation of R.
Another type of incomplete data is record values which usually appear in many real-life applications. Record values arise in climatology, sports, business, medicine, industry, and life testing surveys, among others. These records are commemorating over the period of the time that have been studied. The history of records may show the advancement in science and technology. By considering the record values in various areas of humankind activities, we can evaluate the performance of the societies. In 1952, [17] introduced the distribution of record values into the statistical world. After six decades of his original work, hundreds of papers were devoted to various aspects of the record’s theory. He provided a foundation for a mathematical theory of records. He defined the record values as consecutive extremes appearing in a sequence of independent identically distributed (i.i.d.) random variables. These smallest or largest occurred values are called “lower” or “upper” record values, respectively. Let X1,…,Xn be a sequence of i.i.d. continuous random variables with a cumulative distribution function (CDF) F(x) and its corresponding probability density function (PDF) f(x). For every positive integer k≥1, the sequence of kth lower record times, {L(k), k≥1}, is defined as follows
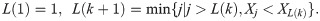
Then the kth lower record value will be denoted by XL(k) and the sequence {XL(k), L(k)≥1} is called the lower record values. For the sake of simplicity, from now on, we shall refer to XL(k) as Xk. As mentioned before, the record values have many applications in industry and engineering. Consider an electronic system that is subject to some shocks like low or high voltage in which both are dangerous for its predefined performance. These shocks could be considered as realizations of i.i.d. variable, and then one can use the record values models to study them. We refer the readers to [18, 19] for more details on the record values and their applications.
The Gumbel distribution is a well-known and popular model due to its wide application in climatology, global warming problems, wind speed, and rainfall modeling, among others. The book of [20] has an extensive list of applications of the Gumbel distribution in various fields of science. [21] has generalized this distribution by exponentiating, in the form of F(x;α) = 1−[1−G(x)]α, where G(x) is the Gumbel density and a>0. Note that exponentiating the standard probability distributions cloud solves the problem of lack of fits that arise when using these distributions for modeling complex data [22]. They showed the power and ability of this generalized distribution in modeling the climatology data by applying it on rainfall data from Orlando, Florida.
In this work, we use a slightly different way to define the exponentiated distributions, i.e., F(x;α) = [G(x)]α, which are called the proportional reversed hazard rate models [23]. The random variable X follows the two-parameter Exponentiated Gumbel distribution if it has the following CDF
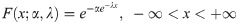
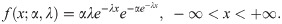
Here α and λ are the shape and scale parameters, respectively. We will denote this distribution by EG(α,λ).
In this section, we consider the maximum likelihood estimation of R = P(X>Y) when X~EG(α,λ) and Y~EG(β,λ), and X and Y are independently distributed. Formal integration shows that
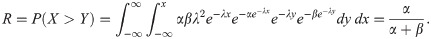
Let X1,X2,…,Xn and Y1,Y2,…,Ym be two independent sets of the lower records from EG(α,λ) and EG(β,σ), respectively. Therefore, the likelihood function of parameters becomes (see [19])
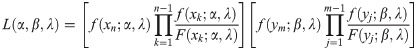
From (2) and (3) the likelihood function is obtained as
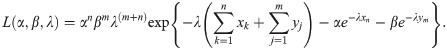
The log likelihood function is given by
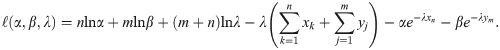
Then, the likelihood equations will be
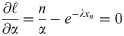
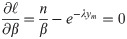
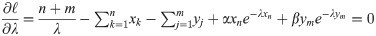
From above equations, we get
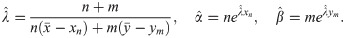
Note that is the harmonic mean of and , which are the MLEs of independent samples of sizes n and m, respectively.
Therefore, by applying the invariant property of ML estimators, the ML estimation of R will be
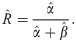
In this section, we obtain the Fisher information matrix of the unknown parameters of EG distribution, which can be used to construct asymptotic confidence intervals.
[19] showed that the PDF of the sth lower record, Xs, is given by
Therefore, the Fisher information matrix of θ = (α,β,λ) will be
The asymptotic covariance matrix of the ML estimators could be achieved via inverting the Fisher information matrix as following
Now, by using the delta method, the asymptotic variance of could be obtained as follows.
Note that the is a function of unknown parameters, and it needs to be estimated. It can be done by plunging the ML estimators of the parameters. Therefore, the (1−γ)% asymptotic confidence intervals of R will be in the form of .
In this section, we attempt to find the Bayes estimator of the parameters. To do so, we consider that the parameters are apriori independent, and they follow gamma distributions, i.e., α~Gamma(a1,b1), β~Gamma(a2,b2), and λ~Gamma(a3,b3). Therefore, the full posterior distribution of the parameters will be
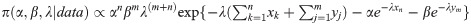
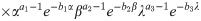
The above posterior does not admit a closed-form and cannot be used directly in the estimation procedure. Then to simulate a random sample from such distributions and perform an approximated inference, the Gibbs sampler could be used. The full conditional distributions of the parameters are as follows:
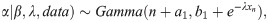
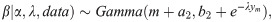
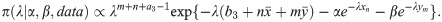
As π(λ|α,β,data) does not have a closed and standard form, one could not produce a sample from this density using direct methods. The Metropolis-Hastings algorithm is a method that can be used to produce a sample from such distributions. As shown in Fig 1, the normal distribution could be a good candidate for the proposal distribution of the Metropolis-Hastings algorithm. Therefore, the algorithm of Gibbs sampling is as follows.

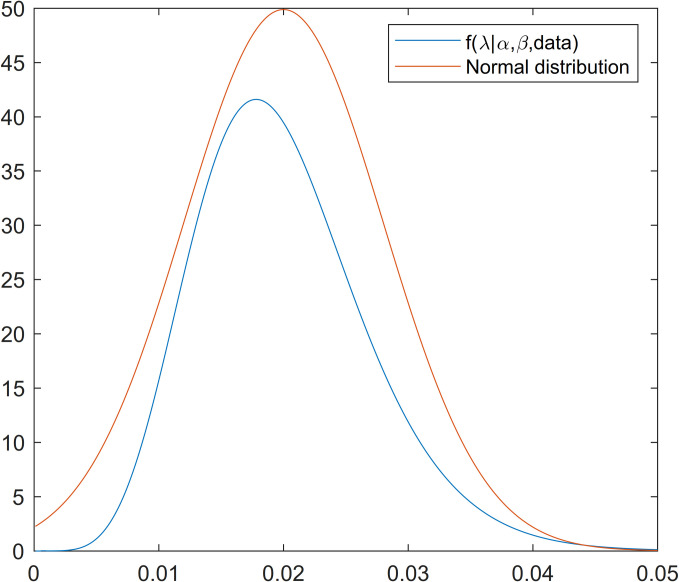
Proposal and posterior density functions of scale parameter.
Step 1: Start with an initial value λ(0).
Step 2: Set t = 1.
Step 3: Generate α(t) from .
Step 4: Generate β(t) from .
Step 5: Use the Metropolis-Hastings algorithm to generate λ(t) from π(λ|α(t−1),β(t−1),data) by using the as a proposal distribution.
Step 5.1: Generate candidate points λ* from and u from . Step 5.2: Set λ(t) = λ* if u≤ρ(λ(t−1),λ*) and λ(t) = λ(t−1) otherwise, when the acceptance probability is given by ρ(λ(t−1),λ*) = min{1,A}, and the acceptance rate is given by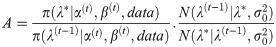
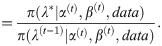
Step 6: Set t = t+1.
Step 7: Repeat steps 3–6, T times.
Once we get a sample from the posteriors, the approximate posterior mean of R, and its variance could be computed as following
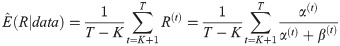
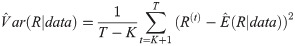
The approximate highest posterior density (HPD) credible interval of R could be constructed using the method proposed in [24].
Let R(K+1)<R(K+2)<⋯<R(T) be the ordered output of the chain, R(t). To construct a 100(1−γ)% approximate HPD credible interval for R, we consider the following intervals,
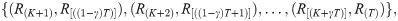
As we show in section 2, the ML estimation of λ does not depend on the value of other parameters; therefore, by plunging the MLE of λ, one can assume that the model contains only two parameters. This assumption makes the procedure of inference easier and straightforward. In other words, we can assume that λ is known, and without loss of generality, we set λ = 1.
As mentioned in section 2, the ML estimator of R is
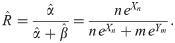
By straight computation, one can see that
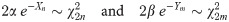
By considering (13), and the fact that Xn and Ym are independent, one can show that
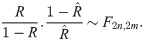
Therefore, the 100(1−γ)% confidence interval for R could be obtained as
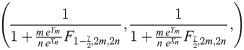
Since we assumed that the parameters are apriori independent with gamma density, the posterior density of α and β are independent and , respectively. Therefore, the posterior distribution of R will be
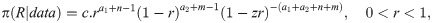
The Bayesian estimation is based on the obtained posterior distribution. According to the assumed loss function, various aspects of the posterior distribution, such as the mean, median, etc., can be used to estimate the parameters. See [25, 26] for more details. By assuming the quadratic loss function, the Bayesian estimation will be the posterior mean which could be computed by considering the following well-known equation
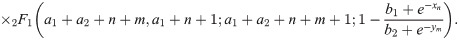
The variance of the Bayesian estimator could be achieved by using
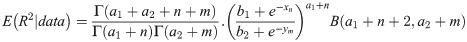
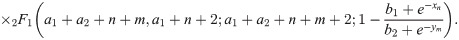
To construct the HPD intervals, as the posterior is not tractable, we can generate a sample from the posterior by using an indirect sampling algorithm, such as the accept-reject method.
In this section, we analyze a set of real strength data, which were taken from ([27], p. 574). These data are originally from [28], which represent the lifetimes of steel specimens tested at 14 different stress magnitudes. Here, we pick up the dataset corresponding to 35.0 and 35.5 stress levels as Dataset 1 (x) and Dataset 2 (y) in Table 1, respectively.

| Dataset 1 (x) | Dataset 2 (y) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 230 | 169 | 178 | 271 | 129 | 156 | 173 | 125 | 852 | 559 |
| 568 | 115 | 280 | 305 | 326 | 442 | 168 | 286 | 261 | 227 |
| 1101 | 285 | 734 | 177 | 493 | 285 | 253 | 166 | 133 | 309 |
| 218 | 342 | 431 | 143 | 381 | 247 | 112 | 202 | 365 | 702 |
Dataset 1 (x) and Dataset 2 (y) correspond to 35.0 and 35.5 stress level, respectively.
We fitted the EG distribution models for two datasets separately and estimated the scale and shape parameters. The Kolmogorov-Smirnov (K-S) goodness of fit test was applied on the datasets. The reported results in Table 2 confirm the well-fitting of the EG distribution to model these data. Moreover, Figs 2 and 3 confirm the appropriate fit of the EG distribution by comparing the empirical and fitted distributions for both datasets.
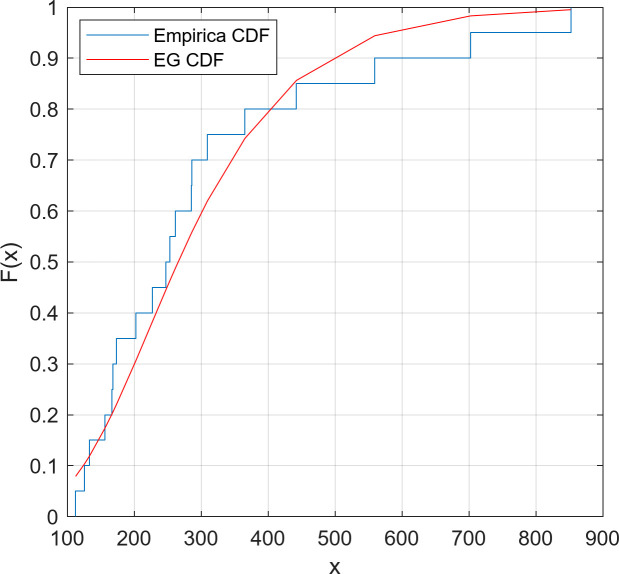
Empirical and fitted CDFs for Dataset 1.
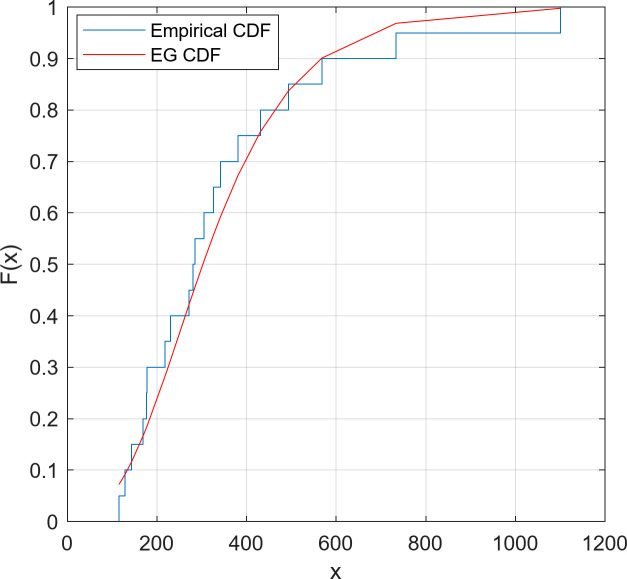
Empirical and fitted CDFs for Dataset 2.
| Dataset | Scale | Shape | K-S | p-value |
|---|---|---|---|---|
| 1 | 0.0071 | 5.9717 | 0.1137 | 0.9326 |
| 2 | 0.0085 | 6.5564 | 0.1408 | 0.7726 |
Now we can use the lower records based on the datasets to drive the ML and Bayesian estimation of parameters. These records for Dataset 1 are 230,169,129,115 and based on Dataset 2 are 156, 125, 112. The corresponding results for ML methods are reported in Table 2. According to this table, it is clear that the scale parameters of the two data sets are almost the same. By assuming equality of the scale parameter, the MLE and the 95% confidence interval of R based on lower records values become 0.5927 and (0.4117,0.7737), respectively. Also, by using Gibs sampling the Bayes estimate and credible interval of R are 0.5893 and (0.4236,0.7641), respectively.
In this paper, we investigated the estimation of the parameters of the two-parameter of exponentiated Gumbel distribution by using lower records values. The maximum likelihood was used to estimate the parameters of the models, and the Fisher information matrix of the unknown parameters is used to construct asymptotic confidence intervals. Furthermore, the Bayes estimator of the parameters and the corresponding credible intervals were obtained by using the Gibbs sampling technique. The methods of estimating (ML and Bayes) were compared via two real data set and showed that the Bayesian estimations are slightly different from the ML ones.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
 Inference of stress-strength reliability for two-parameter of exponentiated Gumbel distribution based on lower record values
Inference of stress-strength reliability for two-parameter of exponentiated Gumbel distribution based on lower record values
 Facebook
Facebook
 Twitter
Twitter
 Linkedin
Linkedin
 Whatsapp
Whatsapp

