 Modernising fish and shark growth curves with Bayesian length-at-age models
Modernising fish and shark growth curves with Bayesian length-at-age models
PLoS ONE


Competing Interests: There are no competing interests.

- Altmetric
Growth modelling is a fundamental component of fisheries assessments but is often hindered by poor quality data from biased sampling. Several methods have attempted to account for sample bias in growth analyses. However, in many cases this bias is not overcome, especially when large individuals are under-sampled. In growth models, two key parameters have a direct biological interpretation: L0, which should correspond to length-at-birth and L∞, which should approximate the average length of full-grown individuals. Here, we present an approach of fitting Bayesian growth models using Markov Chain Monte Carlo (MCMC), with informative priors on these parameters to improve the biological plausibility of growth estimates. A generalised framework is provided in an R package ‘BayesGrowth’, which removes the hurdle of programming an MCMC model for new users. Four case studies representing different sampling scenarios as well as three simulations with different selectivity functions were used to compare this Bayesian framework to standard frequentist growth models. The Bayesian models either outperformed or matched the results of frequentist growth models in all examples, demonstrating the broad benefits offered by this approach. This study highlights the impact that Bayesian models could provide in age and growth studies if applied more routinely rather than being limited to only complex or sophisticated applications.
Introduction
Understanding the growth of aquatic taxa such as fish, sharks, molluscs and crustaceans is imperative for effective fisheries assessments. Specifically, information on growth is used to assess species productivity and define population structure within integrated stock assessment models [1]. Growth information is typically ascertained through length-at-age analysis using models such as a von Bertalanffy growth model [VBGM; 2, 3]. However, biased sampling often hinders growth estimation when not all length or age classes can be effectively sampled [4]. In this situation, additional methods are often applied to account for imperfect data such as constraining model fits or interpolating data through methods such as back-calculation [5, 6]. While these can be effective, in many instances biologically implausible growth estimates can still occur to varying degrees [4].
Length-at-age models are most commonly fit using frequentist approaches such as non-linear estimation [1, 7]. When appropriate length-at-age samples are available, these methods perform adequately and produce the necessary information to inform further population analyses. However, there are often instances where unrepresentative samples compromise growth estimates. For example, large species of sharks (>3 m total length) often have biased samples as fishing gear is size selective and often cannot catch the largest or smallest size classes [8, 9]. These individuals are the most influential to growth estimation as they essentially anchor the ends of the curve at minimum and maximum sizes [1]. Age zero individuals help define the length-at-birth parameter (L0) while the largest individuals strongly influence estimates of asymptotic length (L∞). When omitted, resulting growth curves may adequately describe the length-at-age over the length and age ranges available but may provide parameter estimates that do not appropriately describe the growth of the species [9–11].
Bayesian approaches are an effective tool when frequentist approaches cannot determine appropriate estimates from the data alone. Bayesian methods incorporate prior knowledge into an analysis and produce a combined output using priors along with the data available [12, 13]. The combination of priors and model likelihoods produces posterior distributions for each parameter, which represent the inclusion of additional information in the model. When estimating species growth, prior information can be easily incorporated into length-at-age modelling by creating informative priors for L0 and L∞ based on known length-at-birth (often close to zero for bony fishes) and the species maximum length, respectively. The inclusion of informative priors in Markov Chain Monte Carlo (MCMC) analyses and have proved effective in growth analyses where they have been applied [14–18]. However, of Bayesian approaches for growth estimation are most commonly applied to more complex analyses or datasets such as hierarchical modelling [19, 20], tag recapture data [21] or length-frequency data [22]. It is reasonably rare for Bayesian approaches to be applied to standard length-at-age analyses, despite their successful applications and suitability [14, 23].
The broader use of Bayesian methods in length-at-age analyses by incorporating priors on maximum and minimum lengths could prove to be a valuable advancement in growth modelling. Length-at-birth and maximum length strongly relate to two of the three estimated parameters in growth analyses and are usually used as a cursory check for model appropriateness following an analysis. Their formal inclusion in an analysis is therefore very sensible, hence why it is surprising that the use of Bayesian methods have not flourished. This has likely not occurred for two reasons: 1) there is lack of awareness of how Bayesian models could benefit length-at-age analyses by overcoming basic and common challenges with sampling; and 2) Bayesian analyses are more complicated than frequentist approaches, requiring greater knowledge of statistical distributions, modelling processes, and specialised software [12] which means they are only applied when sophisticated methods are essential. These issues mean that Bayesian methods are often not considered when in fact they could provide an elegant solution to fully considering a species’ biology in any growth analysis.
Here, we demonstrate the effectiveness of Bayesian methods for addressing sampling issues in length-at-age analyses and their benefits. In doing so, we fully document a generalised framework that is an extension of the multi-model paradigm; where multiple models are applied and the best fitting model is selected [24–26]. This framework can be applied to any length-at-age analysis that would normally be undertaken in a frequentist approach. We contend that this approach could be used more regularly to estimate growth and aim to facilitate this by providing an R package ‘BayesGrowth’ [27] that makes this analysis more accessible to a general audience. This package is available at https://github.com/jonathansmart/BayesGrowth.
Materials and methods
Description of generalised Bayesian growth modelling framework
Multi-model paradigm for growth modelling
A contemporary modelling approach rather than the a priori use of the VBGM is to fit multiple growth models to the data and compare their fits using Akaike’s Information Criterion (AIC) [25, 28]. Multi-model approaches are preferred as they reduce the chance of fitting a model that is not well suited to the data. Three growth models are commonly applied to aquatic taxa using a multi-model approach [26]: the von Bertalanffy growth model,
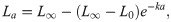
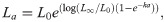
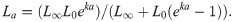
A multi-model approach culminates in model selection via AIC which is calculated as AIC = nlog(σ2) + 2k, k is the total number of parameters +1 for variance (σ2) and n is the sample size. The model with the lowest AIC value (AICmin) has the best fit to the data and is the most appropriate of the candidate models. Remaining models can be ranked using the AIC difference (∆AIC) which can be calculated for each model (i = 1–3) as ΔAIC = AICi−AICmin. Models with ∆AIC of 0–2 have the highest support while models with ∆AIC of 2–10 have considerably less support and models with ∆AIC of >10 have little or no support [29]. AIC differences can be used to calculate AIC weights (AICw) which represent the probability of choosing the correct model from the candidates:
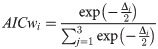
In this study, we extend this multi-model paradigm beyond its this application into a generalised Bayesian framework that can be applied equivalently to this frequentist approach. This framework includes the same models, produces equivalent and interchangeable outputs, and culminates in model selection. Additionally, this generalised Bayesian framework explicitly includes valuable biological information as Bayesian priors.
Generalised framework for MCMC growth estimation
Extending the multi-model paradigm into a Bayesian approach requires the introduction prior information for the growth parameters (k, L0 and L∞). Each parameter requires a prior, which can take one of several different distributions. Length-at-age models are most often fit using multi-variate normal distributions. However, each prior does not need to have the same distribution as its posterior distribution. In this study and the ‘BayesGrowth’ R package, L0 and L∞ have normally distributed priors determined from reported length-at-births and maximum lengths, respectively. The remaining growth parameter (k) has a uniform distribution bounded from zero to a maximum probable value. The use of a uniform distribution produces a “non-informative prior” where no additional information is provided for this parameter. Therefore, in this model, prior knowledge of L0 and L∞ is being included while no prior knowledge is provided for k. This allows the model to fit closely to the species length-at-birth and maximum length while permitting k to fluctuate and produce the necessary curvature. A fourth model parameter, the residual standard error (σ) also requires a prior, which is also uniform. All model priors are bounded at zero as they must remain positive. However, this means that the prior for L0 will become a half-normal distribution when this parameter approaches zero (as will likely occur for teleost fishes). However, for species with lengths-at-birth that are far greater than zero, this prior distribution will automatically become normally distributed. Note that as L0 has a direct biological meaning, it is easier to determine a prior for than t0.
This Bayesian structure is well suited to a multi-model paradigm for several reasons. Firstly, L0, σ and L∞ have consistent interpretations between candidate growth models and therefore the same priors can be used across models. Secondly, as the growth completion parameter (k) is different for each candidate model, the use of an uninformative prior again means that all three candidate models can be specified with identical priors. However, it should be noted that the upper bound for the priors of k and σ used in this framework should be set at values well above the expected estimates of these parameters in each candidate model. For example, an expected estimate of k for the VBGF may be 0.3 yr-1 and therefore a prior of U(0, 0.5) would seem sensible. However, this would not be the case if the expected estimate of k for the logistic mode was 0.7 yr-1 as the prior distribution does not extend to this value. In this example setting a prior of U(0, 0.5) would constrain the fit of the logistic model. Therefore, if consistent priors are to be used across candidate models in this framework then the upper bound of any uniform distribution must suit all models. Setting a cautiously high upper bound is sensible as this won’t influence the model and will have little effect on how quickly a model converges. This consistency in candidate model structure means that model selection is not reliant on the individual model specifications but rather on which model shape best suits the application. This significantly simplifies the use of multi-model approach in Bayesian growth model fitting.
The main outputs of Bayesian models are the posterior distributions of each model parameter. The posterior distribution is determined from a prior distribution and a likelihood distribution using Bayes’ theorem:
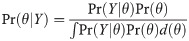
Markov Chain Monte Carlo (MCMC) was used to apply Bayes theorem to growth estimation. MCMC is a process for sampling from a posterior distribution via Markov chains to determine parameter uncertainty from the posterior distribution. Each simulation is a random draw where each is probabilistically related to the previous iteration. The MCMC produces a vector of posterior parameter estimates, which can be summarised using a central tendency (such as the mean, median or mode), and a variance (standard deviation or percentiles). Summarising a normally distributed posterior distribution by using a mean and standard deviation is equivalent to determining a frequentist parameter estimate and standard error.
For a growth curve fit using MCMC, the posterior distributions are influenced by both the length-at-age data (likelihood distributions) and the known species length-at-birth and maximum length (prior distributions). A scenario where the likelihood distributions have narrow variance means that the growth model fits the data well. Therefore, posterior distributions will be strongly weighted towards it. However, a situation where the likelihood distributions have wide variance (due to poor fit or large residuals), posterior distributions will be more strongly influenced by the priors. In this instance, inclusion of prior knowledge of the species maximum length or length-at-birth will adjust the model towards these known values. The inclusion of additional information through priors also produces more precise length-at-age predictions. These are valuable in future analyses that rely on these estimates to convert between ages and lengths. Two circumstances are particularly well suited to Bayesian methods: when data are sparse or when data are unreliable and incomplete [12]. Length-at-age samples regularly fall into these two categories [5], hence the potential improvement that can be offered by MCMC methods.
Model selection for Bayesian models can be accomplished through several different methods. However, leave-one-out-cross-validation (LOOCV) is the most contemporary and robust method presently available [30]. LOOCV estimates pointwise out-of-sample prediction accuracy using the log-likelihood evaluated at the posterior parameter distributions. Using LOOCV, leave-one-out-information-criterion (LOOIC) can be calculated which has the same application as AIC in a frequentist setting. LOOIC weights (LOOICw) for each candidate model can also be calculated and have identical interpretation as AICw for model selection.
BayesGrowth R package
The implementation of MCMC growth models is more computationally demanding and complicated than frequentist growth models. Several computer programs exist that perform the MCMC computations, one of which is ‘Stan’ [31]. Stan allows users to perform MCMC using both Hamiltonian Monte Carlo (HMC) and No U-Turn Sampling (NUTS), both of which are computationally efficient. Stan also calculates LOOIC which is also computationally expensive. Stan can be used in the R programming environment [32] to build MCMC models via the ‘rstan’ R package [33] and perform LOOIC using the ‘loo’ R package [34].
The generalised growth modelling framework presented here has been encapsulated in the BayesGrowth R package [27]. This package provides a series of wrapper functions around rstan models, allowing the users to perform an MCMC growth analysis (using NUTS) much more simply. Three growth models are included in ‘BayesGrowth’: the VBGM, Gompertz and Logistic growth models. These are fit with a normal residual error structure (σ) and their parameters are directly comparable to a standard growth model fit using the ‘nls’ function in ‘R’ [32]. The BayesGrowth package will fit an MCMC model via rstan while providing necessary control to the user. A rstan model object is returned from the estimation function, which allows the user to take advantage of all the auxiliary functions such as model summary statistics and diagnostic plots that exist in the supporting R packages. The BayesGrowth package also contains functions that provide credibility intervals around the growth curve (these are analogous to bootstrapped confidence intervals), as well as functions that facilitate model selection using LOOIC as part of a multi-model paradigm. The only additional step to fit an MCMC model using BayesGrowth is to provide priors based on known length-at-birth and maximum length.
Comparison of Bayesian and frequentist growth model applications
To demonstrate the improvements offered by Bayesian over frequentist growth models, two analyses are presented. The first compares the accuracy and precision of both approaches when using simulated datasets with various sampling complications caused by gear selectivity. The second demonstrates the application of both approaches to four case studies, each of which represents a different species life history or a common sampling problem in growth studies.
The generalised Bayesian framework described previously was used in every application using the Bayesgrowth package. In each application four MCMC chains with 10,000 simulations were used to determine parameter posterior distributions. A burn in period of 5000 simulations was used, and initially, no thinning was performed. All models were checked for convergence using the Gelman-Rubin test, and diagnostic plots produced using the ‘Bayesplot’ R package [35] were examined to check that chains had mixed, and that autocorrelation did not occur. Autocorrelation can be present as each Markov chain simulation is reliant on the previous one and are therefore not independent. Autocorrelation can be accounted for by ‘thinning’, where every nth simulation is kept and the others discarded, thus reducing autocorrelation. Simple models or univariate models often do not require this and in most situations, thinning is not advised as it throws away data and increases runtimes [36]. However, in length-at-age modelling, some autocorrelation can occur, and therefore thinning should be considered when present. Autocorrelation was checked using diagnostic plots from the ‘Bayesplot’ R package [35] and if present, thinning was implemented, and the number of iterations accordingly increased until no autocorrelation occurred. All frequentist models were fit using the AquaticLifeHistory R package [37].
Case studies
To demonstrate the real-world application of Bayesian growth analysis, four examples are provided for species with different life histories or sampling issues. Both a frequentist approach and a Bayesian model are fit to these data. For blue mackerel (Scomber australasicus), an additional model where L0 is fixed at zero is also included. Three models were fit for each species: VBGM, Gompertz and Logistic models with model selection performed using LOOIC. The priors for each species are provided in Table 1. In each case study, the standard errors of L∞ and L0 priors were initially set as 10% of the maximum length and length-at-birth, respectively. These were used in an initial fit and increased or reduced as needed if the initial bias in the growth model estimates remained unresolved. The MCMC diagnostic plots for each case study and the code used to produce them are presented in S1 Appendix.

| Species | Parameter | Prior | Best fitting MCMC Model | MCMC posterior | Best fitting nls model | nls parameter estimates (free L0) | nls parameter estimates (fixed L0) |
|---|---|---|---|---|---|---|---|
| Silvertip shark | L∞ | N(300, 30) | VBGM | 296.2 ± (22.53) | VBGM | 899.4 ± (1429) | - |
| k | U(0, 0.3) | 0.06 ± (0.01) | 0.009 ± (0.02) | - | |||
| L0 | p[0, ∞][N(68, 5)] | 77.22 ± (4.26) | 100.7 ± (6.4) | - | |||
| σ | U(0,100) | 11.71 ± (1.33) | 10.28 | - | |||
| Silky shark | L∞ | N(280, 15) | Logistic | 269 ± (5.41) | Logistic | 268.3 ± (6.05) | - |
| k | U(0, 5) | 0.14 ± (5e-3) | 0.14 ± (6e-3) | - | |||
| L0 | p[0, ∞][N(77, 5)] | 82.3 ± (1.57) | 82.6 ± (1.71) | - | |||
| σ | U(0, 100) | 14.7 ± (0.45) | 14.63 | - | |||
| Reef ocean perch | L∞ | N(47, 0.5) | VBGM | 46.2± (0.5) | Logistic | 30.4 ± (0.4.9) | - |
| k | U(0, 1) | 0.07 ± (3e-3) | 0.27 ± (0.03) | - | |||
| L0 | p[0, ∞][N(1, 0.1)] | 1 ± (0.1) | 0.84 ± (1.4) | - | |||
| σ | U(0,100) | 3.3 ± (0.2) | 2.21 | - | |||
| Blue mackerel | L∞ | N(44, 5) | VBGM | 31.8 ± (0.43) | VBGM (Free and fixed L0) | 37.8± (2.37) | 2.93 ± (0.13) |
| k | U(0, 1) | 0.66 ± (0.04) | 0.15 ± (0.03) | 0.99 ± (0.03) | |||
| L0 | p[0, ∞][N(0, 1e-3)] | 0 ± (8e-4) | 20.9 ± (0.59) | - | |||
| σ | U(0, 100) | 2.43 ± (0.088) | 1.94 | 2.17 |
All lengths are total length (TL) in cm. Values in brackets are the SD and SE of MCMC and frequentist models, respectively. Model results are displayed for the best fitting models, as determined by DIC and AIC (Table 2). An nls model with a L0 fixed at zero was only applied for Blue mackerel.
Reef ocean perch (Helicolenus percoides) from continental shelf-waters off the coast of South Australia were used to demonstrate the MCMC model versus frequentist growth models on a dataset lacking older fish (n = 153). These fish live their entire lives on the seafloor at depths up to 350 m, are long-lived (>40 years) and can attain lengths >40 cm [38, 39]. Ocean perch are live bearing (lecithotrophic)—most bony fish spawn eggs—and produce a gelatinous mass containing fully-developed larvae [40].
Silvertip sharks (Carcharhinus albimarginatus) from Papua New Guinea were used in a length-at-age analysis by Smart et al [10] from a limited sample. Silvertip sharks are born at 63–81 cm total length (TL) and can reach ~300 cm TL [41]. However, the sample in Smart et al [10] contained a length range of 95–250 cm TL from 48 sharks. Consequently, the growth estimates for these data had overestimated values of L0 and L∞. Back-calculation [42] was applied to increase the interpolated sample size and better model L0. However, L∞ was still overestimated with back-calculated data [10]. Here the observed data was used as case study to demonstrate the improvements offered by Bayesian models for both the L0 and L∞ parameters.
Silky sharks (Carcharhinus falciformis) from Papua New Guinea were used in length-at-age analysis by Grant et al [43] from a sample of n = 553. Silky sharks are born at 56–87 cm total length (TL) and can reach ~330 cm TL [41]. Grant et al [43] were able to produce a biologically plausible growth curve from these data, which corresponded to length-at-birth and resembled maximum length. These data are included as an example to compare a Bayesian model to a well performing frequentist growth model
Lastly, Blue mackerel (Scomber australasicus) were collected off the southern coast of New South Wales, Australia (n = 789). Blue mackerel are a small pelagic fish (forage fish) found throughout the Pacific Ocean in coastal and continental shelf waters. Younger fish usually live in inshore waters, while larger adults form schools in deeper waters (40–200 m) across the continental shelf [44]. Blue Mackerel reach sizes of up to 44 cm and at least 8 years in the Great Australian Bight [45, 46]. This dataset illustrates the fit of the Bayesian model to data for a fast-growing species where smaller fish are under-represented.
Selectivity scenario simulations
To compare the performance of Bayesian and frequentist growth models, three length-at-age datasets for scenarios with different selectivity functions were simulated from a VBGM. The results of the Bayesian and frequentist models were then compared to the known values used to simulate these data. The length-at-age data were drawn from a VBGM with a multiplicative error structure:
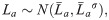
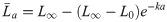
The probability of sampling different ages in each scenario was dependent on the selectivity-at-age a (Sa) and the survivorship-to-age a (la). Survivorship-to-age a is important as relatively fewer older individuals are present in a population as the probability of survival decreases with age. Therefore, the probability of sampling any given La was expressed using a multinomial observation process where the probability of sampling an individual of age a was:
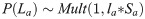
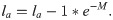
Three selectivity functions were used in each scenario:
1) a logistic function where selectivity increases with age,
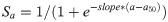
2) a logistic function where selectivity decreases with age,
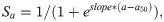
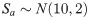
The code to reproduce this analysis is provided in S2 Appendix.
Choice of informative priors
As the priors for L0 and L∞ are normally distributed, they require a standard error to be specified which will affect how wide or narrow the prior distributions are. As a more precise prior will provide greater weight to the posterior this means that the choice of standard error can be influential. Particularly, this will occur when sample sizes are low as the precision of the likelihood component of the Bayesian model will be lower. To demonstrate the effect of prior precision for L0 and L∞ on Bayesian growth models; two of the case studies (Silvertip sharks and silky sharks) were examined further. These two examples were chosen as they have large lengths-at-birth and therefore the L0 parameters will be greater than zero and the standard errors of the priors will be more influential. In these examples, the Bayesian models were fit three times using the original priors (base case priors) and priors with less precision that were set at 25% and 50% of the mean value used for each prior. The silvertip shark example demonstrates the effect prior precision with a low sample size (n = 48) while the silky shark example demonstrates this for a larger sample size (n = 553). The code to reproduce is provided in S3 Appendix.
Results
Case studies
The Bayesian analysis improved the length-at-age results for silvertip sharks, blue mackerel and ocean perch, while returning negligible differences to length-at-age estimates from the frequentist model for silky sharks (Fig 1). The Bayesian model for silvertip sharks produced similar length-at-age results to the frequentist model between ages 3 and 14, after which the Bayesian model asymptoted sooner (Fig 1). This provided a more appropriate L∞ that corresponded to the species biology Similarly, the L0 was estimated lower for the Bayesian model which more closely matches the known length-at-birth.

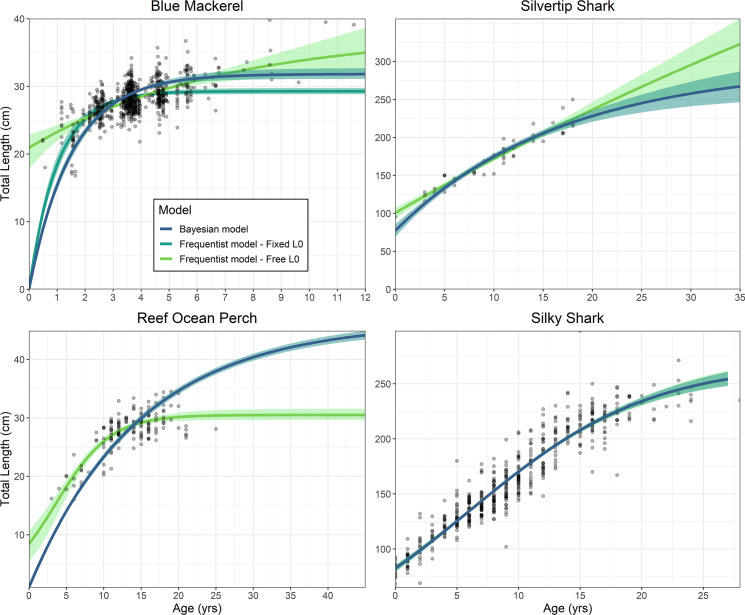
A comparison between length-at-age estimates determined from an MCMC analysis performed using Bayesian and frequentist models for the four case studies: Blue mackerel, ocean perch, silvertip shark and silky shark.
All four case studies had a frequentist model with a freely estimated L0 included. Additionally, blue mackerel had a frequentist model with an L0 fixed at zero. Shaded areas correspond to 95% credibility intervals for the Bayesian length-at-age estimates and bootstrapped confidence 95% intervals for the frequentist models.
Blue mackerel had greatly improved fits provided by the MCMC model, which fit well to the length-at-age data and had an L0 and L∞ that better matched known length-at-birth and maximum length (Table 1). The two frequentist models provided poor fits as neither produced biologically appropriate parameters. The model with a fixed L0 underestimated L∞ while, the model with a freely estimated L0 overestimated this parameter and L∞ (Fig 1).
The frequentist model for ocean perch initially appears to fit the data well (Fig 1). However, prior knowledge that this species can reach 42 years of age and 47 cm TL demonstrates that the absence of older and large fish has compromised these estimates. The Bayesian model was able to overcome this by producing a growth curve with appropriate length-at-age estimates and L∞ (Fig 1). A VBGM was selected by LOOIC which differed to a Logistic model that performed better in the frequentist analysis (Table 2).
| Species | Model | LOOIC | LOOICw | AIC (Free L0) | AICw (Free L0) | AIC (fixed L0) |
|---|---|---|---|---|---|---|
| Silky shark | VBGM | 4357 | 0 | 4348 | 0 | - |
| Logistic | 4322 | 1 | 4321 | 1 | - | |
| Gompertz | 4333 | 0 | 4332 | 0 | - | |
| Silvertip shark | VBGM | 374 | 0.69 | 365.8 | 0.36 | - |
| Logistic | 378 | 0.09 | 366.1 | 0.31 | - | |
| Gompertz | 376 | 0.22 | 365.9 | 0.33 | - | |
| Reef ocean perch | VBGM | 1516 | 1 | 1392.01 | 0.05 | - |
| Logistic | 1799 | 0 | 1386.69 | 0.72 | - | |
| Gompertz | 1679 | 0 | 1388.98 | 0.23 | - | |
| Blue mackerel | VBGM | 7282 | 1 | 6925.11 | 0.69 | 7102.73 |
| Logistic | 14946 | 0 | 6929.41 | 0.08 | Did not converge | |
| Gompertz | 14620 | 0 | 6927.28 | 0.23 | Did not converge |
Best fitting models identified in bold typeface.
The Bayesian model and frequentist model for silky sharks produced only marginally different results to one another (Fig 1; Table 1). The best fitting model for both frequentist and Bayesian methods was the Logistic model, as determined by AIC and LOOIC, respectively (Table 2). Therefore, a Bayesian model produces effectively the same results as a frequentist model when a sufficient sample is available to estimate growth without need for S1–S3 Appendixes.
Simulated length-at-age comparisons
The Bayesian framework provided more accurate and precise length-at-age and growth parameters in eight out of nine simulations (Table 3; Fig 2). The frequentist model in the dome-shaped selectivity scenarios provided an L∞ that was similar to the actual L∞ value but had large imprecision (Table 3). However, the L0 parameter was overestimated with very little precision (Table 3; Fig 2). Consequently, k was also underestimated and imprecise (Table 3). Conversely, The Bayesian model provided good precision for all three parameters with accurate estimates of k and L0 and a reasonable estimated of L∞ (Table 3). Therefore, the resulting growth curve closely matched the actual growth curve that the data was drawn from (Fig 2).
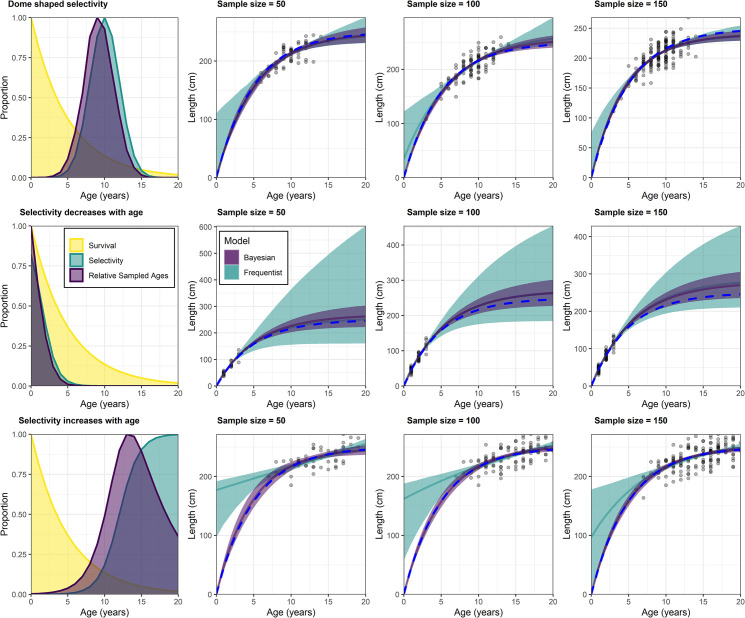
Accuracy and precision of Bayesian (purple) and frequentist (green) growth models when fit to simulated data drawn from different selectivity functions and sample sizes (n = 50, n = 100 and n = 150). Growth models with different sample sizes are shown in each row for the corresponding selectivity curves with relative sampled ages (product of selectivity and survivorship at age) in the left-hand panels. Shaded areas around the growth curves are the 95% bootstrapped confidence intervals for the frequentist models (green shading) and the 95% Bayesian credibility intervals (purple shading) for the Bayesian growth models. The true growth curve used to generate the length-at-age data is represented by the dashed blue line.
| Frequentist estimate (SE) | Bayesian estimate (SE) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Scenario | Parameter | Known value | Priors | n = 50 | n = 100 | n = 150 | n = 50 | n = 100 | n = 150 |
| Dome based selectivity | L∞ | 250 | N(275, 27.5) | 246.9 (15.15) | 268.4 (21.16) | 239 (9.0) | 249.59 (9.34) | 257.31 (7.82) | 240.3 (5.27) |
| k | 0.2 | U(1e-5, 0.5) | 0.20 (0.07) | 0.15 (0.05) | 0.22 (0.05) | 0.19 (0.02) | 0.19 (0.01) | 0.22 (0.02) | |
| L0 | 0 | p[0, ∞][N(0, 1e-3)] | 0.01 (91.68) | 34.76 (37.3) | 0.01 (44.0) | 0.01 (0.01) | 0.01 (0.01) | 0.01 (0.01 | |
| Selectivity decreases with age (Logistic) | L∞ | 250 | N(275, 27.5) | 255.6 (49.1) | 269.6 (40.41) | 285.9 (38.82) | 269.01 (24.22) | 271.4 (22.38) | 278.2 (21.3) |
| k | 0.2 | U(1e-5, 0.5) | 0.20 (0.05) | 0.18 (0.04) | 0.17 (0.02) | 0.19 (0.02) | 0.18 (0.02) | 0.18 (0.02) | |
| L0 | 0 | p[0, ∞][N(0, 1e-3)] | 0.16 (1.39) | 0.18 (0.97) | 0.08 (0.8) | 0.01 (0.01 | 0.01 (0.01 | 0.01 (0.01 | |
| Selectivity increases with age (Logistic) | L∞ | 250 | N(275, 27.5) | 286490 (1.838e+09) | 321.5 (162) | 261 (13.62 | 248.68 (6.13) | 252.63 (4.26) | 250.57 (3.5) |
| k | 0.2 | U(1e-5, 0.5) | 0.00001 (0.088) | 0.04 (0.08) | 0.13 (0.06) | 0.21 (0.03) | 0.2 (0.02) | 0.2 (0.01) | |
| L0 | 0 | p[0, ∞][N(0, 1e-3)] | 176.8 (29.65) | 161.8 (39.8) | 96.79 (55.24) | 0.01 (1.65) | 0.01 (0.01) | 0.01 (0.01) | |
The scenarios where selectivity decreases with age via a logistic function represents a gear selectivity that targets younger individuals. In this scenario the frequentist estimates of k and L0 were accurate and precise, while L∞ had low precision (Table 3). The Bayesian estimates were also more accurate and precise in these scenarios for each parameter, with the only exception being the simulation with a sample size of 50 (Table 3). In this scenario, the frequentist estimates were more accurate. However, they also had unreasonably large imprecision, especially when bootstrapped confidence intervals were calculated (Fig 2). The Bayesian growth curves matched the actual growth curve very closely with good precision (Fig 2). However, L∞ remained overestimated in comparison to the other selectivity scenarios. This was caused by the L∞ prior of 275 cm which was used to represent that maximum length is often larger than L∞. Subsequently, the posterior of L∞ in this scenario was strongly weighted toward this prior (Table 3).
The scenarios where selectivity increased with age via a logistic function represents gear selectivity that targets older individuals while excluding juveniles. The frequentist model for these scenarios provided precise and accurate estimate of L∞ but an overestimate of L0 for all three sample sizes (Table 3). Therefore, k was underestimated (Table 3). The estimates of L0 also had a very low level of precision, although this didn’t affect length-at-age estimates for older age classes (Table 3; Fig 2). The Bayesian model for these scenarios provided precise parameter estimates that closely matched the actual growth parameters (Table 3). The resulting growth curve had a high level of accuracy and precision (Fig 2).
The Bayesian models were less influenced by sample size in each selectivity scenario when compared with the frequentist models (Fig 2). Posterior precision increased with sample size in each scenario while there was little change in the overall accuracy of each growth curve (Table 3; Fig 2). Conversely, the frequentist models were more strongly influenced by sample size, particularly in the scenario where selectivity increased with age. Here the accuracy of L0 was particularly influenced by sample size.
A L∞ prior that was intended to represent a maximum length that was larger than the actual L∞ was appropriate for the dome-shaped selectivity scenario and the scenarios where selectivity increased with age (Table 3; Fig 2). Here, consistent model estimates were produced regardless of sample size. In the scenario where selectivity decreased with age, it was apparent that this prior was more influential and caused some overestimation of L∞ regardless of the sample size (Table 3; Fig 2). This highlights that when older individuals cannot be sampled, particular care should be placed on selecting a prior for L∞.
Choice of informative priors
Altering the precision of L0 and L∞ priors only affected the silvertip shark application where the sample size was n = 48 (Table 4; Fig 3). The silky shark application which had a much larger sample size (n = 553), had only negligible changes to its posteriors and resulting growth curve (Table 4; Fig 3). The posteriors for all parameters changed according to the priors used for silvertip sharks with L0 and L∞ better matching the known maximum size and length-at-birth when the priors were more precise (Table 4). Additionally, the standard error of the with L0 and L∞ had much greater precision when a narrower prior was used (Table 4). The greatest amount of variation occurred for with L∞ which increased by approximately 40% when a weakly informative prior used rather than the base case prior (Table 4). However, the results of all of these Bayesian models provide more precise parameter estimates than the corresponding frequentist models for silvertip sharks (Tables 1; 4).
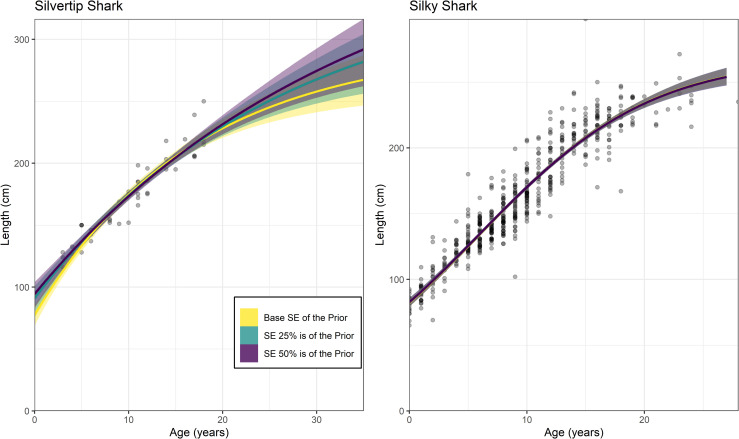
A comparison of Bayesian growth models fit to silvertip and silky sharks using different levels of precision on the L0 and L∞ priors.
The base case scenarios (yellow) represent the priors used in each case study (Table1). The other scenarios include priors where the standard error (SE) is 25% of the value used in each prior (green) and 50% of the value used in each prior (purple).
| Silvertip sharks (n = 48) | ||||||
|---|---|---|---|---|---|---|
| Parameter | Base case prior | SE is 25% of mean | SE is 50% of mean | |||
| Prior | Posterior (SE) | Prior | Posterior (SE) | Prior | Posterior (SE) | |
| L∞ | N(300, 30) | 296.2 (22.53) | N(300, 75) | 357 (47.71) | N(300, 150) | 419.7 (84.32) |
| k | U(0, 0.3) | 0.06 (0.01) | U(0, 0.3) | 0.04 (0.01) | U(0, 0.3) | 0.03 (0.01) |
| L0 | p[0, ∞][N(68, 5)] | 77.22 (4.26) | p[0, ∞][N(68, 17)] | 91.13 (5.24) | p[0, ∞][N(68, 34)] | 94.55 (5.23) |
| σ | U(0,100) | 11.71 (1.33) | U(0,100) | 10.79 (1.2) | U(0,100) | 10.64 (1.16) |
| Silky Sharks (n = 553) | ||||||
| L∞ | N(280, 15) | 269 (5.41) | N(280, 70) | 268.7 (5.78) | N(280, 140) | 268.7 (5.79) |
| k | U(0, 5) | 0.14 (0.01) | U(0, 5) | 0.14 (0.01) | U(0, 5) | 0.14 (0.01) |
| L0 | p[0, ∞][N(77, 5)] | 82.3 (1.57) | p[0, ∞][N(77, 19.25)] | 82.59 (1.67) | p[0, ∞][N(77, 38.5)] | 82.58 (1.66) |
| σ | U(0, 100) | 14.7 (0.45) | U(0, 100) | 14.68 (0.45) | U(0, 100) | 14.67 (0.45) |
Discussion
Bayesian methods have previously been applied in shark and fish growth models with great effectiveness [14, 16, 17, 23, 47]. However, these applications have been mostly limited to more complex analyses rather than typical length-at-age analyses, presenting an opportunity to broaden their use. Given that Bayesian models can formally include information on species biology, it is surprising that this technique has not become more common for growth modelling as is the case in other ecological studies [48]. The generalised framework presented here directly addresses this by providing a flexible approach that could be broadly applied to standard growth analyses and will provide improved or equivalent results to a frequentist approach.
The greatest improvement offered by this generalised Bayesian framework is the ability to account for missing older individuals caused by decreased selectivity with age. It is common for older individuals to be under sampled, particularly for large or long-lived species as the probability of surviving to older ages can be low for fished populations. While methods such as fixing L0 or applying back-calculation can account for the opposite scenario (missing younger individuals), to date there have been few approaches that have effectively accounted for missing older individuals. Some studies have attempted to fix L∞ to the known maximum size [49–51]. However, this has resulted in poor model performance when applied as part of a multi-model paradigm [51]. Here, the inclusion of a prior on maximum length effectively improved the estimate of L∞ when older individuals were missing in both the simulated example and the Silvertip shark case study. To date, this may be the greatest solution to under sampling of older individuals due to gear selectivity or age truncation that has hindered numerous growth studies [9–11].
While using maximum length as a prior for L∞ was effective in these examples, there may situations when further refinement is required. For example, L∞ represents the average length of fully grown individuals [7, 52] and therefore maximum length is likely to be larger than this value for many species. In situations where L∞ is underestimated, using maximum length as the L∞ prior will be beneficial as it will increase the L∞ posterior and account for this underestimation, as demonstrated here for Blue Mackerel. However, when L∞ is overestimated, using maximum length as the prior for L∞ will be less influential than if it were underestimated. The Silvertip example provided in this study demonstrates this, although biologically appropriate results were still produced. The simulations where selectivity decreased with age demonstrated that when older individuals were sparse, some overestimation of L∞ occurred when setting its prior based on a hypothetical maximum length that was 5% larger than the actual value. This demonstrates that the prior for L∞ requires the most consideration, especially when older individuals are under sampled in order to gain the most benefit from a Bayesian approach.
Contemporary growth modelling approaches incorporate a multi-model paradigm, where several models are fit and the best performing model is selected [24, 25]. This approach has been extended into the Bayesian space through several studies that applied multiple models [20, 53–56]. However, one complication posed by a Bayesian approach is that parameters differ between models. This requires different priors to be specified; a complication which had no previous solution [57]. Therefore, many of multi-model Bayesian applications have compared models that were similar or variants of the same model shape (i.e. VBGM). Model selection of Bayesian growth models with fundamentally different shapes is more complicated, since a candidate model that is poorly specified may not be selected, even if its shape best fits a species’ growth form. This would occur if an inappropriate prior were place on a candidate model’s growth completion parameter (k). In this situation the resulting posterior distribution may be heavily weighted to the prior and effect model selection. Determining priors for the growth completion parameters is more complicated as these parameters have no biological interpretation. Therefore, applying a weakly information or uninformative prior for k may be more appropriate to avoid miss specification. The framework presented here allows consistent priors to be applied across three different candidate models. This is achieved by ensuring that all models are parameterised to use L0 and L∞—which have informative priors—while applying uninformative priors on remaining parameters. The application of a Bayesian multi-model framework is now greatly simplified, because model specification will not affect model performance, allowing the most suitable model for the species to be selected.
The results of both analyses presented here demonstrate the improvements offered by Bayesian over frequentist approaches. Bayesian models provided the closest match to known growth parameters that were used to generate length-at-age data based on different selectivities. In each example, frequentist models tended to over or under-estimate length-at-ages depending on missing age classes that were omitted due to selectivity. Meanwhile, the inclusion of priors allowed the Bayesian models to better match those growth curves, providing more accurate and precise results. Selectivity has been previously examined through similar simulation studies with Frater and Stefansson [58] determining techniques that can account for this bias. However, these techniques required knowledge of the selectivity function which is not always known and can cause increased parameter bias if miss-specified [4]. The Bayesian framework presented here overcame these selectivity scenarios without knowledge of the selectivity function, offering a simple method that can improve growth model results without the risk of introducing additional bias.
Improved growth estimates were also produced in three out of four case studies presented here using the Bayesian framework. In each of these examples, known issues with the growth curves were overcome with previously poorly estimated L0 or L∞ now better matching biologically plausible values. The only example where no definitive improvement was produced was for Silky sharks, which had a larger sample size and included all age classes [43]. In this example, almost identical length-at-age estimates were produced by both Bayesian and frequentist approaches. One could therefore argue that if sufficient samples were available, then there is no need for a Bayesian approach, and the added complexity may introduce error. However, an opposing conclusion would be that applying a Bayesian approach can only improve growth estimates. We therefore conclude that there is little to be lost by using a Bayesian approach, and instead, much to be gained.
Several alternatives to a Bayesian approach have been applied extensively in growth studies to account for sampling limitations. Given that L0 and L∞ have biological interpretations, it has been common to fix these parameters at corresponding values. Fixing L0 at zero is especially common for bony fish species, which have a larval phase and are born at a size close to zero. However, growth model parameters co-vary [19], and fixing one parameter to a specific value biases the others [59]. For example, fixing L0 to a single value is not advised as slight inaccuracies in assigning the true length-at-birth can adversely bias the remaining parameters [59]. Some authors have also attempted to fix both L0 and L∞ while only estimating k [49–51]. However, this resulted in a poor model fit in each of these studies and was quickly dismissed as a candidate model in multi-model approaches. Gwinn et al [4] examined this topic in detail by simulating a population that was exploited under different fishery selectivity types and attempting to overcome biased sampling using different strategies. However, there was no overall strategy that could be applied across all sampling circumstances without biasing estimates. Finally, back-calculation has been applied to several species to determine theoretical lengths-at-age from older individuals [5, 42, 60]. This can effectively overcome sampling bias when large individuals have been sampled but smaller individuals are omitted. However, this cannot account for situations where larger individuals are under sampled, which often leads to overestimating L∞ [9–11]. The Bayesian approach presented here is the first technique that has addressed the under sampling of large individuals and their effect on growth estimation.
There are several advantages to the Bayesian framework we present, aside from the improved growth estimates demonstrated in these examples. It is intuitive to include known biological traits of a species as explicit components of a growth model. Maximum length and length-at-birth are regularly deemed synonymous with L0 and L∞, respectively [4, 59], and thus acknowledging this through priors is reasonable. Posterior distributions of model parameters also contain a great deal more information than point estimates and standard errors provided by frequentist models. For example, posterior distributions may reveal multiple modes, or show the probability mass to be concentrated in a certain area [12]. Convergence issues are easier to diagnose in Bayesian models as more information is returned to user. The user can use this additional information to step through the diagnostic tests outlined in this study and improve model fit.
The Bayesian approach detailed here is widely applicable, however, there are a few minor disadvantages to discuss. Firstly, there are more diagnostics to examine for Bayesian models than frequentist models, which can make them seem overly complex for simple analyses. However, if a model has been correctly specified, then these diagnostics add substantial confidence to the analysis. Secondly, one area where Bayesian statistics lags behind frequentist statistics is user-friendly software [12], which has likely prevented the uptake of Bayesian methods for growth modelling. The goal of our study was to directly address this with a user-friendly R package for Bayesian growth modelling. Lastly and most importantly, users of this approach need to embrace a Bayesian philosophy to model fitting. Frequentist statisticians would argue that the need to introduce priors is a weakness of Bayesian approaches and introduces subjectivity [12]. However, some degree of subjectivity is often unavoidable in any analysis, and here, the strength of Bayesian methods lies in its direct acknowledgement and justification. Including a range of sensible priors will often produce the same results as a frequentist model when data is unbiased [12], as demonstrated here in the case study for silky sharks.
Determining priors for the four case studies in the present study was not complicated. In each example, a standard error was initially set as 10% of the maximum length and length-at-birth. This was used in an initial fit and was increased or reduced as needed if the initial bias in the growth model estimates remained unresolved. The resulting growth estimates in all four instances produced growth estimates that fit the length-at-age data well and provided estimates of L0 and L∞ that corresponded to species’ biology. The same approach was used in the selectivity scenarios and produced appropriate results in each application. The model framework here does not require priors of k and σ to be determined on a case-by-case basis, as these priors are uninformative. Therefore, these priors only require an upper bound to their uniform distributions. Whether these upper bounds are appropriate is determined by whether or not their resulting posteriors are normally distributed.
In any Bayesian analysis, the user should judiciously document and explain their choice of priors, which for length-at-birth and maximum length is straightforward. However, the standard error of each of these distributions can be more complicated to determine. A narrower standard error may weigh the posterior distribution more toward the prior distribution than the likelihood distribution, although the extend of this can be dependent on sample size. For example, a wider standard error applied when sample size is large may be insufficient to update the posterior from the likelihood distribution, as seen in the present study for Silky sharks. Therefore, a narrower standard error on certain parameters may be required to ensure prior information is adequately incorporated into the model. Alternatively, when sample size is small, narrower priors can have far more influence on the posteriors, as seen in the present study for Silvertip sharks. In this example, a narrower prior on L∞ was justified as the initial frequentist model could not match the biology of the species. Wide priors on L∞ improved the results but the Bayesian model that provided the best representation of species’ biology was produced with narrower priors on L0 and L∞. In some instances, information may be available to determine a standard error for the L0 and L∞ priors. A recent example for L0 was performed using predicted lengths-at-age-zero from back-calculations to determine the mean and standard error of this prior [61]. Similarly, a recent study also used the lengths of the largest individuals documented in the literature to determine the prior mean and standard error for L∞ [62]. Justifications such as these can be important when using Bayesian models and demonstrate the opportunity for researchers to include as much biological information as possible in their analysis, thus improving the results. These considerations are the most important decisions when implementing a Bayesian growth model and can add the most benefit to the analysis.
Conclusions
The generalised framework presented here demonstrates the impact that Bayesian methods could make for standard length-at-age studies. Previously, Bayesian has been more complicated to implement than frequentist alternatives for growth modelling, since considerably more statistical and programming expertise is needed. However, the BayesGrowth R package helps remove this barrier and introduce more users to Bayesian growth modelling. Its application in the present study to the four case studies and selectivity simulations, demonstrates the improvements offered over comparable frequentist models. Additionally, this generalised framework may be further tailored by users who seek more specified or sophisticated models. For example, some occasions may require different priors, error structures or candidate models to be applied in a similar framework. Examples already exist where biphasic or Schnute models have been used in Bayesian growth models [17, 23, 63]. Likewise, more sophisticated models can incorporate hierarchical structures [16, 19, 22, 64], identify growth morphs [54], account for autocorrelation in back calculations [65], or examine environmental drivers [64, 66]. The framework we have presented sits alongside this existing body of research by providing an entry point to Bayesian growth modelling that can be applied to standard growth modelling scenarios. With the information and guidance provided in this study, there is great opportunity for the field of Bayesian growth modelling to continue to expand and possibly become the standard approach for estimating fish growth.
Acknowledgements
We would like to thank Michael Grant and Colin Simpfendorfer for providing the data for Silky Sharks. The Blue Mackerel data was collected as part of the sampling program for the Commonwealth Small Pelagic Fishery on behalf of the Australian Fisheries Management Authority. Jonathan Carroll assisted with publishing the ‘BayesGrowth’ package. We thank the reviewers of this study for their constructive comments.
References
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66