 Tolerance interval testing for assessing accuracy and precision simultaneously
Tolerance interval testing for assessing accuracy and precision simultaneously
PLoS ONE


Competing Interests: The authors have declared that no competing interests exist.

- Altmetric
Tolerance intervals have been recommended for simultaneously validating both the accuracy and precision of an analytical procedure. However, statistical inferences for the corresponding hypothesis testing are scarce. The aim of this study is to establish a whole statistical inference for tolerance interval testing, including sample size determination, power analysis, and calculation of p-value. More specifically, the proposed method considers the bounds of a tolerance interval as random variables so that a bivariate distribution can be derived. Simulations confirm the theoretical properties of the method. Furthermore, an example is used to illustrate the proposed method.
1. Introduction
When assessing whether an analytical procedure is suitable for its intended purpose, the impacts of accuracy and precision are usually considered. “Accuracy” usually refers to the expectation of the effect response from the product, whereas “precision” is the variability of the effect response from the product. In practice, the two parameters are unknown and need to be estimated. If the two parameters are validated separately, then multiple adjustments of the controls of family-wise error rates for making the wrong decision are necessary. However, an analytical procedure usually allows for a product to have a relatively small value of variation, accommodating a relatively greater value of bias than a product with a greater value of variation. For these reasons, the United States Pharmacopeia (USP) guideline <1210> Statistical Tools for Procedure Validation [1] recommends a two-sided tolerance interval as being useful for establishing a single criterion to simultaneously validate both accuracy and precision; in other words, an assessment is useful when assessing whether 100γ percent of a population, say X, is located within a prespecified acceptable interval (cL, cU).
Tolerance interval approaches have been widely used in the area of sampling acceptance criteria, however, the relationship between hypothesis testing and tolerance interval sampling acceptance plan were scarcely discussed [3]. A hypothesis testing for assessing the drug effect is usually required, and thus controlling the type I error rate and achieving the desired power are important. Therefore, Novick et al. [2] and Dong et al. [3] suggested two one-sided tolerance interval tests to dose content uniformity tests, delivered dose uniformity tests, and dissolution tests. In their applications, the hypotheses H0L:Pr(X<cL)≥P1 and H0U:Pr(X<cU)≥P2 were tested, respectively, where X is a random variable from a population with prespecified constants cL, cU, P1, and P2. However, Novick et al. had pointed out that the use of two one-sided tolerance intervals is correct for controlling of the type I error rate only if the variability of the population is sufficient small. If so, the use of the tolerance interval test seems to be meaninglessness since it is essentially equivalent to testing merely the population mean. Moreover, whether the variability of the population is small enough is usually unknown in practice.
In this study, a two-sided tolerance interval test is considered. As pointed out by Chiang et al. [4], there must be two unknown parameters θL and θU leading to P(θL<X<θU)≥γ. Therefore, when being linked to the prespecified acceptable interval, one of the following four situations must be true: (i) cL≤θL and θU≤cU, which is what we expect; (ii) θL≤cL and θU≤cU, which must indicate that the expectation of X has a negative bias from our expectation; (iii) cL≤θL and cU≤θU, which must indicate that the expectation of X has a positive bias from our expectation; and (iv) θL<cL and cU<θU, which must indicate that the variability of X exceeds what we expected. Consequently, situations (ii) and (iii) represent a lack of accuracy, whereas situation (iv) represents a lack of precision; these three situations should be rejected. Therefore, it is indicated that the statistical hypotheses for testing θL and θU are as follows:
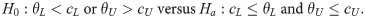
The corresponding test statistic for hypotheses (1) is exactly a two-sided tolerance interval because, by definition, a 100(1−α)% confidence 100γ% content two-sided tolerance interval of X satisfies the following equation:
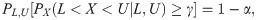
On the other hand, the sample size determination for a tolerance interval is traditionally used to achieve a desired width for the interval [6, 7]. In doing so, only the control of precision is considered in the traditional sample size determination for a tolerance interval. Now, if hypothesis testing and the tolerance interval sampling acceptance plan are linked, determining sample size for a desired power of the tolerance interval test is equivalent to providing a sufficiently large probability of the tolerance interval falling within a prespecified acceptance interval; that is, accuracy and precision are taken into consideration simultaneously in the sample size determination. Therefore, evaluating the required sample size for a two-sided tolerance interval test is also an important aim of this study.
The rest of this paper is arranged as follows. In Section 2, the tolerance interval proposed by Howe [8] and recommended by the USP guideline is described. Then, a power function is derived from the asymptotic distribution for the lower and upper tolerance limits. The sample size can then be set to reach the required level of power. The p-value of the tolerance interval test is derived by a similar procedure. In Section 3, the proposed method is illustrated by an example drawn from the USP guideline. The good properties of the method are confirmed by simulations in Section 4. We study the required sample size as a function of the parameters on sample size in this section. The last section provides final remarks and discussion.
2. Tolerance interval testing
2.1. Statistical assumption and interval estimation
Let Xi be the reportable response for i = 1,…,n. Suppose that these responses are independent and identically distributed normal variables such that
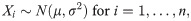
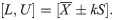
Obviously, appropriately setting the acceptable limits cL and cU is the key point for the correct assessment of accuracy and precision. In doing so, cL and cU are recommended to be at least the expected values of μ±3σ since it is well-known that 99.73% of X is included within this range. If γ is not large, for example, 90%, then the acceptance limits may be changed to μ±2σ; that is, 95.45% of X should be included.
2.2. Sample size determination
According to the rejection rule of the two-sided tolerance interval testing, the power function is written as
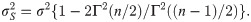
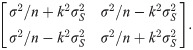
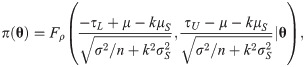
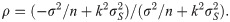
Since the asymptotic distribution of the lower and upper tolerance bounds has been derived, it can be applied to calculate the p-value of the tolerance interval test. Specifically, given observations of L and U –say l and u, respectively–the p-value is
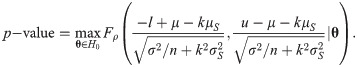
3. Example
The example of high-performance liquid chromatography mentioned in the USP document [1] is used to illustrate the proposed study. The unit of measurement for each reportable value is the mass fraction of drug substance expressed in units of mg/g and does not change as the level of concentration varies. The sample mean and sample standard deviation are 992.81 and 4.44, respectively, with a sample size of 9. For a content level of 90% and a confidence level of 90%, the Howe approximation of k is
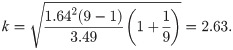
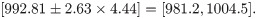
If the mean and standard deviation are used to design a new test with the same acceptable range, the proposed sample size determination indicates that, for a content level of 90% and a confidence level of 90%, merely 4 subjects are required to meet a power of 80%. In fact, the theoretical power, via the use of the proposed method, is 92.96%. If the acceptable range is reduced to [990, 1010], the proposed sample size determination indicates that for a content level of 90% and a confidence level of 90%, 43 subjects are required to meet a power of 80%. More specifically, when the sample size is 43, the lower and upper tolerance limits follow a bivariate normal distribution asymptotically with the mean vector [998.58, 1001,42]’ and covariance matrix
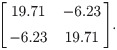
4. Simulation and numerical study
The purpose of this simulation is to investigate whether the proposed sample size determination can reach the targeted level of statistical power under several combinations of design parameters. As in the USP example, we set, without loss of generality, μ from 0 to 1 in increments of 0.5 and σ from 3 to 4 in increments of 0.5. The acceptable region (cL,cU) = (−c,c) with c ranging from 10 to 12 in increments of 1. The confidence level and content level are α = 0.1 and γ = 0.1, respectively. Consequently, there are 27 sets of parameters for the simulation. One million random samples of a size determined by the proposed method are generated from the normality assumption in (1) for each set ofparameter components. The empirical power is the proportion of the 1,000,000 two-sided tolerance intervals that are contained in the criterion (−c,c). The coverage probability is simultaneously verified, and the empirical result is the proportion of the 1,000,000 lower and upper tolerance limits, say l* and u*, satisfying F(u*)−F(l*)>90%, where F(.) is the marginal cumulative distribution function of (1).
The simulation results are presented in Table 1. There are several points we wish to make. First, for the 27 different sets of parameters, all of the empirical powers are greater than the desired level of 80%, which demonstrates that the proposed sample size determination can provide sufficient power under various sets of parameters for validating both accuracy and precision simultaneously based on the two-sided tolerance interval. Moreover, the asymptotic and empirical powers are quite consistent since all of the absolute differences between the two values are less than or equal to 0.0027. In addition, the simulation study shows that the resultant power is stable even when the sample size is very small. For example, the minimum sample size is 7 for μ = 0, σ = 3, and c = 12; the difference between the asymptotic and empirical powers is merely -0.0027. Finally, the empirical coverage probabilities are approximately 90%.

| Total sample | Coverage | Power | |||||
|---|---|---|---|---|---|---|---|
| μ | σ | c | size | Probability | Asymptotic | Empirical | Difference |
| 0.0 | 3.0 | 10 | 10 | 0.8974 | 0.8401 | 0.8391 | -0.0010 |
| 11 | 8 | 0.8982 | 0.8377 | 0.8369 | -0.0008 | ||
| 12 | 7 | 0.8982 | 0.8592 | 0.8565 | -0.0027 | ||
| 0.0 | 3.5 | 10 | 15 | 0.8975 | 0.8196 | 0.8201 | 0.0005 |
| 11 | 11 | 0.8978 | 0.8090 | 0.8100 | 0.0010 | ||
| 12 | 9 | 0.8972 | 0.8200 | 0.8204 | 0.0003 | ||
| 0.0 | 4.0 | 10 | 25 | 0.8982 | 0.8133 | 0.8141 | 0.0008 |
| 11 | 17 | 0.8976 | 0.8155 | 0.8158 | 0.0003 | ||
| 12 | 13 | 0.8972 | 0.8259 | 0.8267 | 0.0007 | ||
| 0.5 | 3.0 | 10 | 10 | 0.8972 | 0.8236 | 0.8241 | 0.0004 |
| 11 | 8 | 0.8976 | 0.8255 | 0.8254 | -0.0001 | ||
| 12 | 7 | 0.8988 | 0.8500 | 0.8485 | -0.0014 | ||
| 0.5 | 3.5 | 10 | 16 | 0.8968 | 0.8281 | 0.8284 | 0.0003 |
| 11 | 12 | 0.8973 | 0.8383 | 0.8372 | -0.0011 | ||
| 12 | 9 | 0.8974 | 0.8089 | 0.8101 | 0.0012 | ||
| 0.5 | 4.0 | 10 | 27 | 0.8979 | 0.8151 | 0.8161 | 0.0009 |
| 11 | 18 | 0.8967 | 0.8222 | 0.8220 | -0.0001 | ||
| 12 | 13 | 0.8970 | 0.8122 | 0.8129 | 0.0007 | ||
| 1.0 | 3.0 | 10 | 11 | 0.8979 | 0.8243 | 0.8243 | -0.0001 |
| 11 | 9 | 0.8978 | 0.8530 | 0.8508 | -0.0021 | ||
| 12 | 7 | 0.8982 | 0.8231 | 0.8233 | 0.0001 | ||
| 1.0 | 3.5 | 10 | 18 | 0.8973 | 0.8175 | 0.8182 | 0.0007 |
| 11 | 13 | 0.8972 | 0.8327 | 0.8322 | -0.0005 | ||
| 12 | 10 | 0.8976 | 0.8324 | 0.8325 | 0.0001 | ||
| 1.0 | 4.0 | 10 | 33 | 0.8977 | 0.8050 | 0.8059 | 0.0010 |
| 11 | 20 | 0.8975 | 0.8111 | 0.8116 | 0.0005 | ||
| 12 | 14 | 0.8965 | 0.8081 | 0.8091 | 0.0010 |
Next, the impacts of the magnitudes of the mean, standard deviation, and criterion on sample size determination are explored in Fig 1. The figure demonstrates that the required sample size increases as the mean and standard deviation increase and decreases as the criterion increases. Note that here, a non-zero mean indicates a bias of accuracy. The relation between the sample size and parameters is, therefore, intuitively correct because the increases in bias and variability must increase the number of samples required to achieve the targeted level of power. On the other hand, the increase in the acceptable margin facilitates the validation of accuracy and precision; hence, the required sample size decreases.

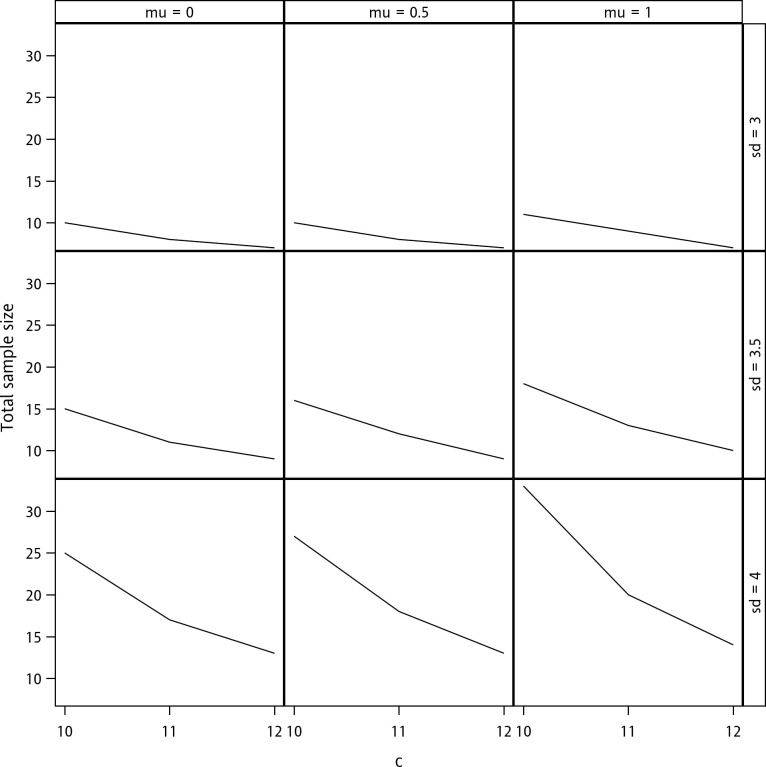
Sample size determination with a confidence level of 90%, a content level of 90%, and a desired power of 80%.
The terms “mu” and “sd” denote μ and σ respectively.
5. Discussion and final remarks
Tolerance intervals have been recommended, for example, by the abovementioned USP document, to simultaneously assess accuracy and precision. This study provides a connection between two-sided hypothesis testing and a two-sided tolerance interval-based assessment. Simulations show that the proposed approach provides sufficient and consistent results compared with the theoretical values on various combinations of parameters even when the sample size is small.
Though, we do not test the magnitude of the proportion γ. How large it is required for the proposed test is still of interest. Intuitively, a higher γ leads to a wider interval. However, the width seems to be unimportant when applying a tolerance interval as a test statistic since we can always set an appropriate acceptance interval for the test. On the other hand, under normal assumptions, an increase in γ results in the precision becoming more important in the assessment. Therefore, the issue may lie in how to balance the importance between accuracy and precision in our assessment.
Currently, the calculation of the exact tolerance factor is not prohibitive. For example, the k.factor() function in the tolerance package [10] for R calculates the exact k-factor. However, it is known that the tolerance factor is a function of the sample size, while the required sample size is unknown for achieving a desired power and must be evaluated by the proposed sample size determination formula. Hence, an approximation of the tolerance factor with a closed-form can simplify the calculation. There are several approximations for the tolerance factor; for example, Krishnamoorthy and Mathew [7] suggested the use of the squared root of , where is the 100γth quantile of a noncentral chi-square distribution with a noncentral parameter of 1/n. Via an additional simulation with the same settings, we find that this approximation would overestimate the coverage probability (by approximately 92%) and requires a slightly larger sample size (1 to 3) to achieve the desired power than Howe’s approximation. On the other hand, although Howe’s approximation underestimates the coverage probability, the difference between Howe’s result and the desired coverage probability is small and can be omitted. As a result, we recommend using Howe’s approximation in the tolerance interval testing.
For testing H0:μ≤kL or μ≥kU versus Ha:kL<μ<kU with prespecified constants kL and kU, we can separate the test into two one-sided tests, where each side controls the type I error rate of α, and the overall type I error rate is still α. This is true because it is impossible for μ to be smaller than kL and larger than kU simultaneously. In contrast, for the proposed tolerance interval test, both the lower and upper acceptance margins might be exceeded simultaneously because of a large variability. As pointed out in the introduction, if necessary, we know that the tolerance interval test has to divide into two one-sided tests for positive bias and negative bias, respectively, and one two-sided test for variability. If so, whether each of the two one-sided tests with a significance level of α controls the overall type I error rate of α is in question. On the other hand, a two-sided tolerance interval with 100(1−α)% confidence itself has naturally controlled the type I error rate of α for the test. Therefore, it is unnecessary to separate the main test into three tests.
We, in fact, do not investigate the control of the type I error rate in the simulation. Alternatively, the preservation of the coverage probability is verified in the simulation study. The reason is that there are three scenarios fitting the null hypothesis, and this leads to difficulty in designing and analysing the simulation study. Second, as mentioned previously, by using a tolerance interval with 100(1−α)% confidence as the test statistic, the type I error rate can naturally be controlled for its corresponding test. As a result, if the coverage probability is satisfied, then the type I error rate can be controlled.
Acknowledgements
This research is part of collaborative work with Mycenax Biotech Inc. (Zhunan, Taiwan). Thanks are due to two referees for their detailed, constructive and thoughtful comments and suggestions which we believe have led to a significant improvement to this paper.
References
1
2
3
4
5
6
7
8
9
10