 A new regression model for bounded response variable: An alternative to the beta and unit-Lindley regression models
A new regression model for bounded response variable: An alternative to the beta and unit-Lindley regression models
PLoS ONE


Competing Interests: The authors have declared that no competing interests exist.

- Altmetric
A new distribution defined on (0,1) interval is introduced. Its probability density and cumulative distribution functions have simple forms. Thanks to its simple forms, the moments, incomplete moments and quantile function of the proposed distribution are derived and obtained in explicit forms. Four parameter estimation methods are used to estimate the unknown parameter of the distribution. Besides, simulation study is implemented to compare the efficiencies of these parameter estimation methods. More importantly, owing to the proposed distribution, we provide an alternative regression model for the bounded response variable. The proposed regression model is compared with the beta and unit-Lindley regression models based on two real data sets.
1 Introduction
In the last decade, modeling of the bounded data sets is increased its popularity. These kinds of data sets appear in many fields such as finance, actuarial and medical sciences. The statistics literature has very limited distributions defined on (0,1). The best known distributions defined on (0,1) are beta, Topp-Leone by Topp and Leone [1] and Kumaraswamy by Kumaraswamy [2] distributions. To increase the modeling accuracy of the data sets on (0,1), several distributions have been proposed by researchers. For instance, the unit-Lindley by Mazucheli et al. [3], unit-inverse Gaussian by Ghitany et al. [4], unit-Birnbaum-Saunders by Mazucheli et al. [5], exponentiated Topp-Leone by Pourdarvish et al. [6], transmuted Kumaraswamy by Khan et al. [7], log-xgamma by Altun and Hamedani [8], log-weighted exponential by Altun [9] and unit-improved second-degree Lindley by Altun and Cordeiro [10].
Although the beta distribution is widely used to model data sets on bounded interval, it has deficiency to model extremely left-skewed and leptokurtic data sets. The moments of the Topp-Leone distribution are not in explicit forms which is important to make appropriate parametrization on the density function for regression modeling. Additionally, even if the moments of the Kumaraswamy distribution are in explicit forms, they contains gamma function which destroys the re-parametrization of the density function. We aim to introduce a new distribution on (0,1) interval to remove the deficiencies of the existing distributions for modeling the extremely skewed data sets. The Bilal distribution introduced by Abd-Elrahman [11] is used to generate a new distribution employing the appropriate transformation. The resulting distribution is called as log-Bilal distribution since we use Y = exp(−X) transformation. After obtaining the log-Bilal distribution, we obtain its statistical properties such as moments, incomplete moments and quantile function. The important question is that do we need this distribution? To answer this question, we summarize the importance of the log-Bilal distribution: (i) the log-Bilal distribution has simple and closed-form expressions for its statistical functions (ii) the properties of the log-Bilal distribution are derived in explicit forms without any special mathematical functions, (iii) the proposed distribution provides more flexibility than existing distributions for the shapes of hazard rate function, (iv) thanks to its simple mathematical functions, we introduce a new regression model based on the log-Bilal density to model the extremely skewed dependent variables with associated covariates.
We summarize the concepts of the remaining sections: the moments, incomplete moments, quantile function, and exponential family property of the log-Bilal distribution are obtained in the next section. Section 3 is devoted to the parameter estimation methods. The efficiencies of these methods are compared in Section 4. The log-Bilal regression model is introduced in Section 5. Section 6 contains the results of the data analysis. The paper is ended with concluding remarks in Section 7.
2 The log-Bilal distribution
Let random variable (rv) X represents the Bilal distribution which has the following probability density function (pdf)
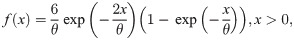
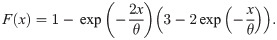
Following the idea of Altun and Hamedani [8] and Altun [9] and using the Y = exp(−X) transformation on the Bilal distribution, the pdf of the log-Bilal distribution is
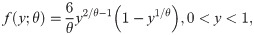
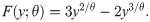
Some possible pdf shapes of the log-Bilal distribution are displayed in Fig 1. From these figures, it is clear that the proposed distribution can be used to model the different types of the data sets defined on the unit-interval such as right and left skewed as well as nearly symmetric data sets.

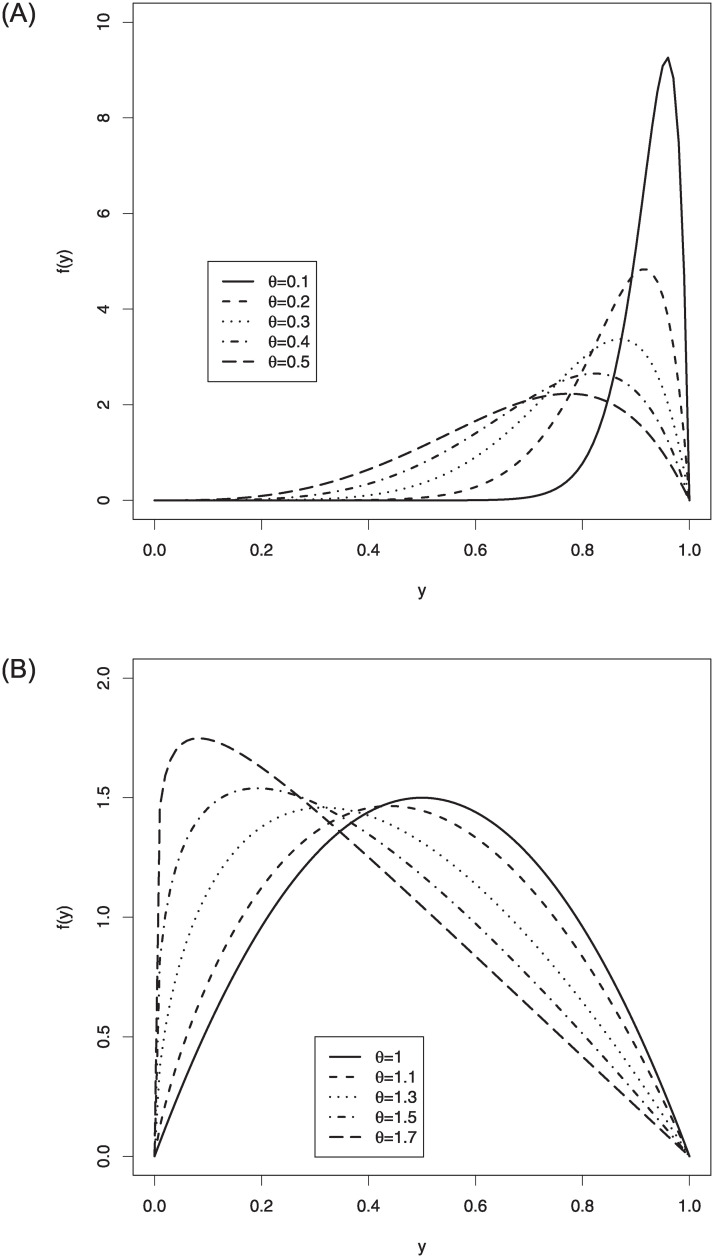
The pdf shapes of the log-Bilal distribution.
The survival function (sf) and hazard rate function (hrf) of Y are, respectively,
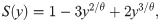
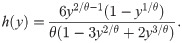
Fig 2 displays hrf shapes of the log-Bilal distribution. As seen from these plots, the hrf shapes of the log-Bilal distribution can be increasing and bathtub. The right side of Fig 2 gives information about the hrf regions of the log-Bilal regression according to the different values of the parameter θ.
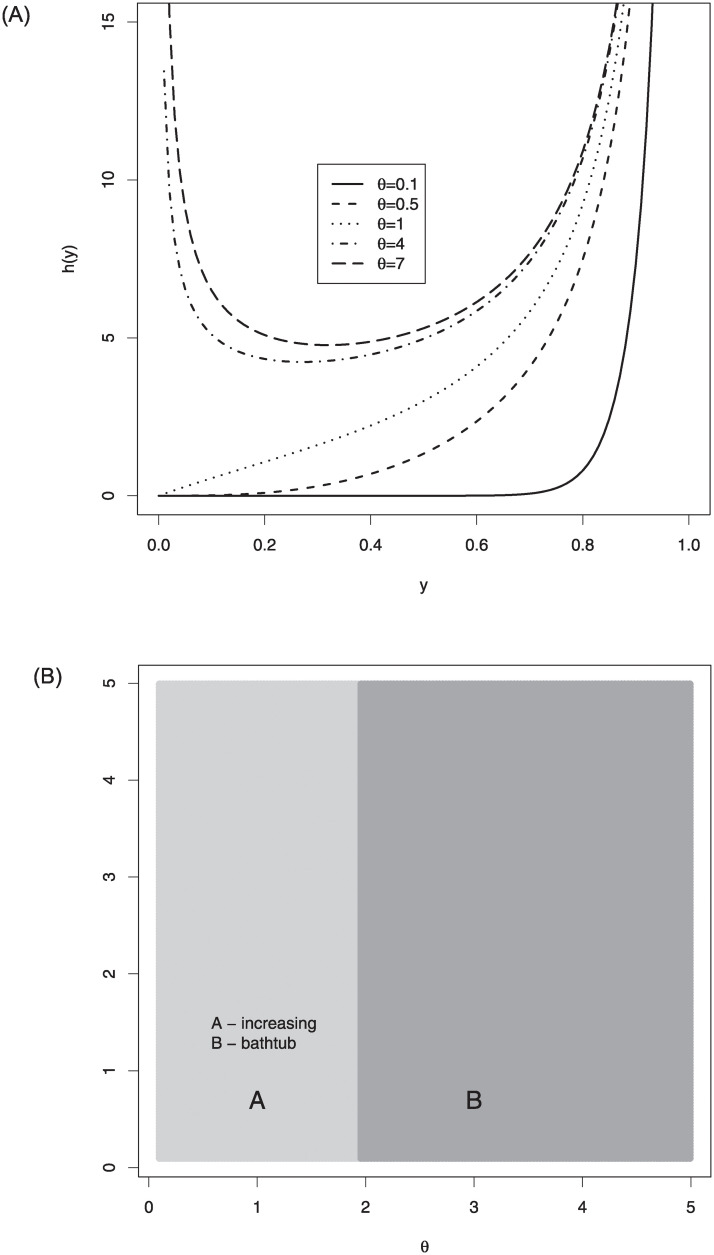
The hrf plots (left) and hrf regions (right) of log-Bilal distribution for selected parameter values.
The quantile function of Y is given by
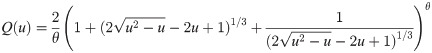
Algorithm 1 Generating random variables from log- Bilal(θ) distribution
1. Set the parameter θ,
2. Generate ui ∼ U(0, 1),
3. Calculate
4. Repeat steps 2 and 3 n times.
2.1 Moments
The kth raw moment of Y is
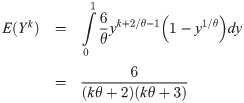
Using (8), the first and second raw moments of Y are given, respectively, by
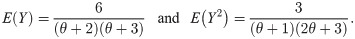
The variance of Y is obtained from the its first and second raw moments as
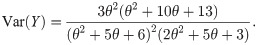
It is easy to conclude that the mean and variance of the log-Bilal distribution decreases when the parameter θ increases.
2.2 Incomplete moments
The rth incomplete moment of Y is
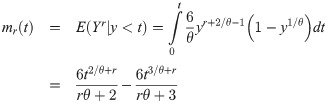
The incomplete moments of random variables are important tools to measure the inequalities like Gini measure (see, Butler and McDonald [12] for details).
2.3 Exponential family
The pdf of any distribution should be expressed in the following form to be a member of exponential family.
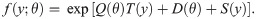
The pdf of the the log-Bilal distribution can be expressed as follows
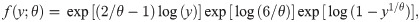
3 Estimation
We use four estimation methods to discuss the parameter estimation process of the log-Bilal distributions. These estimation methods are maximum likelihood estimation (MLE), method of moments (MM), least squares estimation (LSE) and weighted least squares estimation (WLSE). Detailed pieces of information on these estimation methods are given in the rest of this section.
3.1 Maximum likelihood
Let y1, …, yn be a random sample from the log- Bilal distribution. The log-likelihood function of the log-Bilal distribution is
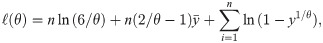
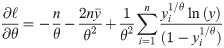
The MLE of θ, say, , is the solution of (11) for zero. There is no explicit form solution for (11). Therefore, it should be solved iteratively or direct maximization of (10) can be viewed as the other choice. Here, the direct maximization of (10) is preferred by using the optim function of R software.
3.2 Method of moments
The MM estimation method is a popular method when the raw moments of the distribution have simple forms. The MM estimator of θ can be easily obtained by equating the first theoretical moment of the log-Bilal distribution to the sample mean, which gives
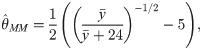
3.3 Least squares
Assume that the y(1), …, y(n) be ordered sample of y1, …, yn following the log-Bilal distribution. The LSE of θ is obtained by minimizing
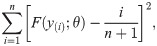
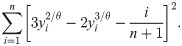
3.4 Weighted least squares
The minimization of the below function gives the WLSE of the parameter θ.
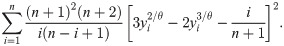
4 Simulation
We compare the efficiencies of the MLE, MM, LSE and WLSE methods in estimating the parameter of the log-Bilal distribution. The algorithm given in Section 2 is used to generate random variables from the log-Bilal distribution. The simulation results are interpreted based on the following quantities.
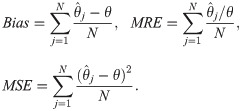
These kind of statistical measures such as means square erros (MSEs) and mean relative errors (MREs) are used to compare the different approaches deciding the best model under pre-determined scenarios (see, Zeng et al., [13, 14]). The statistical software R is used to obtain numerical results for the simulation study. We choose the parameter value θ = 1.7, the simulation replication is N = 10, 000 and the sample size is n = 20, 25, 30, …, 300. If the estimation methods yield an asymptotically unbiased estimation of θ, we expect to see that MSEs and biases approach the zero. On the other hand, MREs should be near the one. The simulation results are displayed in Fig 3. As seen from these figures, MLE method approaches the desired values of biases, MSEs and MREs faster than other estimation methods. Therefore, MLE method is more appropriate than other methods for estimating the parameter of the log-Bilal distribution.
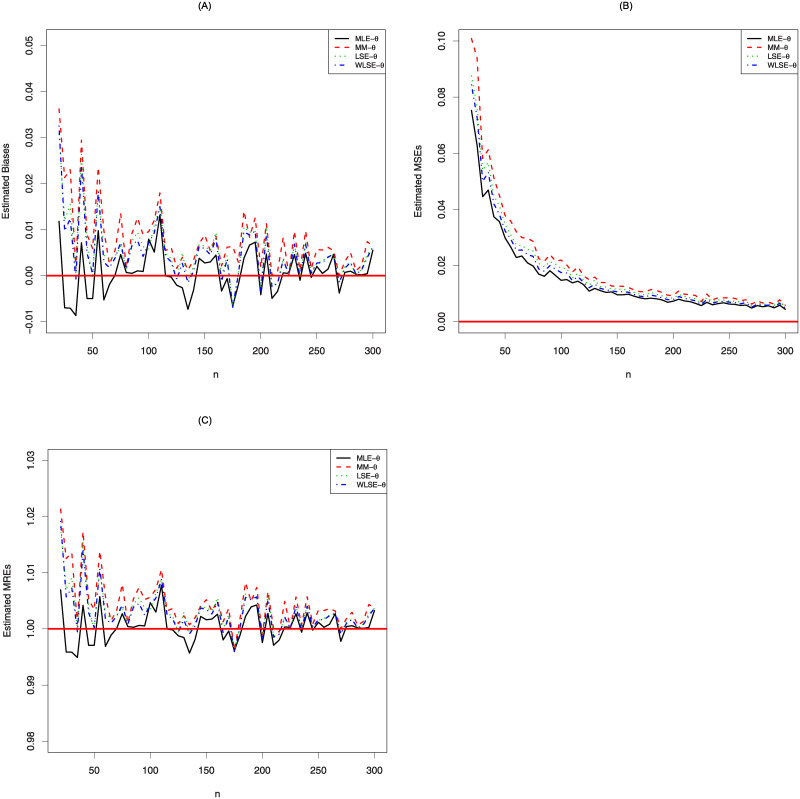
The simulation results of the log-Bilal distribution.
5 The log-Bilal regression model
Now, we introduce a new regression model for bounded response variable as an alternative to the beta and unit-Lindley regression models. Let θ = 2−1({μ/(μ + 24)}−1/2 − 5), then the pdf of log-Bilal distribution takes the form
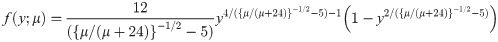
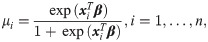
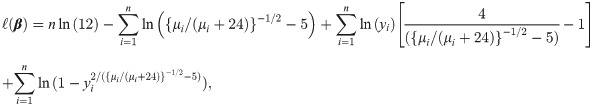
5.1 Residuals analysis
To check the model accuracy of the fitted log-Bilal regression model, the randomized quantile residuals introduced by Dunn and Smyth [15] is used. The randomized quantile residuals are given by
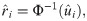
6 Empirical studies
In this section, the log-Bilal distribution and log-Bilal regression model are compared with existing models. Two real data set are analyzed to prove the usefulness of proposed distribution in modeling the real data sets.
6.1 Dwellings without basic facilities
Better Life Index (BLI) is calculated for the OECD countries as well as Brazil, Russia and South Africa to compare the countries based on 12 indicators which effect the quality of the life. Here, we use one of the variable of BLI measured in the year of 2017, dwellings without basic facilities which is defined as a percentage of the population living in a dwelling without indoor flushing toilet. The data set is available at https://stats.oecd.org/index.aspx?DataSetCode=BLI. This data set is used to compare the real data modeling performance of the log-Bilal distribution with the following competitive models: beta, Kumaraswamy, Topp-Leone and unit-Lindley.
The competitive distributions as well as the log-Bilal distribution are fitted to the data used by means of R software. After fitting the distribution to data, the MLEs of the parameters of the fitted distributions with their standard errors (SEs) are obtained. Besides, the formal goodness-of-fit tests such as Kolmogorov-Smirnov (K-S), Cramér-von Mises (W*) and Anderson-Darling (A*) are applied to decide the suitability of the distributions on the data used. Akaike Information Criteria (AIC) and Bayesian Information Criteria (BIC) are widely used criteria to choose the best statistical model. These statistics are used for comparison of the fitted models and selection of the best model (see, Chen et al., [16, 17]).
Table 1 shows the MLEs of the parameters for the fitted models to the dwellings without basic facilities data, corresponding SEs, and goodness-of-fit statistics as well as AIC and BIC values. As seen from the results of K-S tests with corresponding p-values, the all fitted distributions, except the unit-Lindley, provide adequate fits. However, the log-Bilal distribution has the lowest values of the AIC, BIC, A* and W* statistics which indicate that the proposed distribution is the best choice for the data used.

| Models | Parameter estimations | AIC | BIC | A* | W* | K-S | p-value | |
|---|---|---|---|---|---|---|---|---|
| Beta(α, β) | 0.2847 | 1.4017 | -114.1408 | -110.8657 | 1.8818 | 0.2546 | 0.2032 | 0.0868 |
| 0.0518 | 0.3917 | |||||||
| Kumaraswamy(α, β) | 0.3367 | 1.6076 | -117.0740 | -113.7988 | 1.7423 | 0.2317 | 0.1610 | 0.2785 |
| 0.0599 | 0.3519 | |||||||
| Topp-Leone(θ) | 0.3069 | -112.9418 | -111.3042 | 2.2026 | 0.3074 | 0.1867 | 0.1414 | |
| 0.0498 | ||||||||
| unit-Lindley(λ) | 0.0732 | 492.8384 | 494.4760 | 7.9700 | 1.4892 | 0.9699 | <0.001 | |
| 0.0084 | ||||||||
| log-Bilal(λ) | 4.7063 | -118.9374 | -117.2998 | 1.7032 | 0.2254 | 0.1504 | 0.3567 | |
| 0.5491 |
Fig 4 displays the estimated densities of the models on the histogram of data and estimated functions of the log-Bilal distribution. The right panel of Fig 4 plays an important role to convince the readers in favor of log-Bilal distribution.
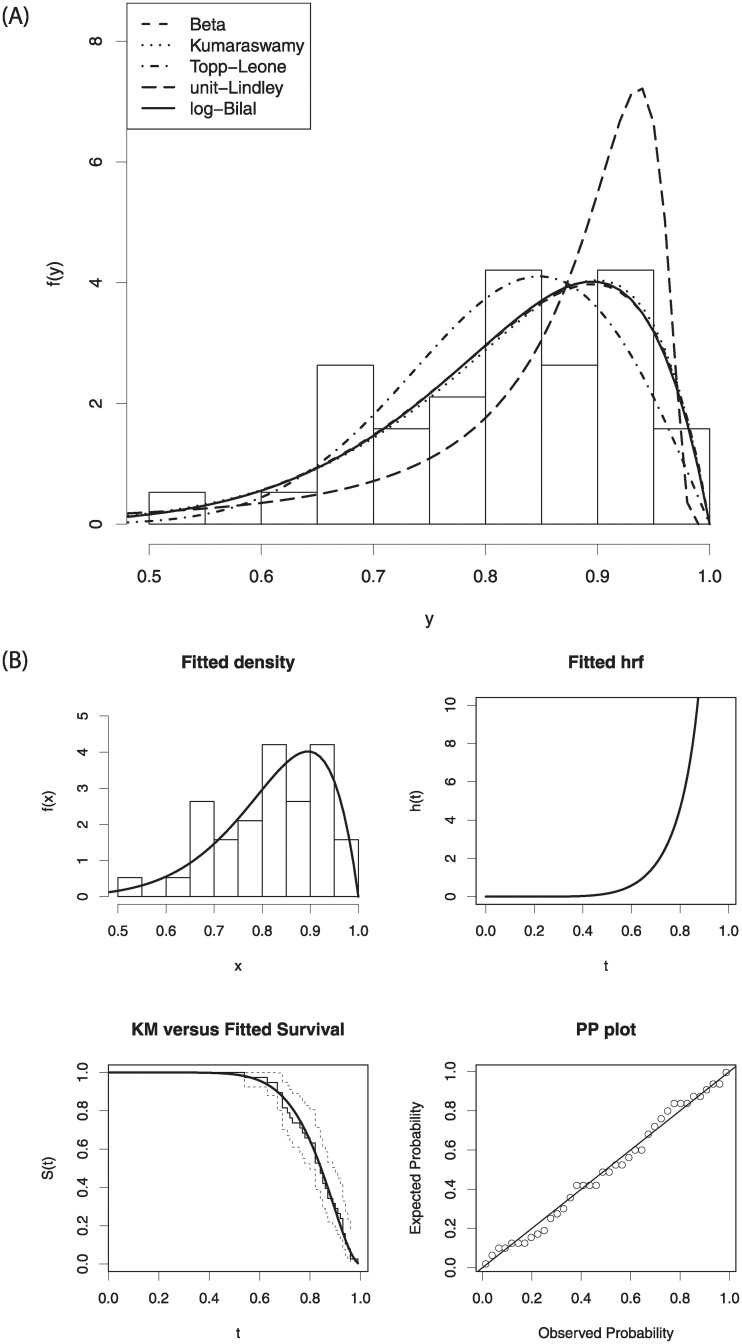
The estimated pdfs of the fitted distribution (left-panel) and some fitted functions of the log-Bilal distribution (right-panel).
6.2 Education attainment
Here, the performance of the log-Bilal regression model is compared with the beta and unit-Lindley regression models. The used data set comes from the BLI of OECD countries, measured in the year of 2017. The data source is https://stats.oecd.org/index.aspx?DataSetCode=BLI.
The educational attainment values of the OECD countries (y) is considered as response (dependent) variable The goal is to explore the effects of following covariates on the conditional mean of the response variable: homicide rate (HR), dwellings without basic facilities (DWBF), and labor market insecurity (LMI). The logit link function which ensures that the estimated mean lies between 0 and 1, is used for all fitted regression models. The fitted regression model is
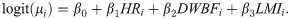
Table 2 lists the MLEs, SEs, and corresponding p-values, AIC and BIC for the beta, unit-Lindley, and log-Bilal regression models. The parameter φ represents the dispersion parameter of the beta regression model. Based on the figures in Table 2, all estimated regression parameters are found statistically significant for beta and log-Bilal regression models. Based on the estimated regression parameters of the log-Bilal regression model, it is concluded that when the homicide rate and labor market insecurity increase, the educational attainment decreases in the OECD countries. On the other hand, when the dwellings without basic facilities increases, the educational attainment increases in the OECD countries.
| Parameters | Beta | unit-Lindley | log-Bilal | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Estimate | S.E. | p-value | Estimate | S.E. | p-value | Estimate | S.E. | p-value | |
| β0 | 1.9208 | 0.1570 | <0.0001 | 1.6263 | 0.1887 | <0.0001 | 2.1136 | 0.2122 | <0.0001 |
| β1 | -0.0674 | 0.0173 | <0.0001 | -0.0543 | 0.0304 | 0.0739 | -0.0705 | 0.0270 | 0.0089 |
| β2 | 0.0434 | 0.0182 | 0.0172 | 0.0521 | 0.0263 | 0.0477 | 0.0724 | 0.0340 | 0.0334 |
| β3 | -10.9688 | 2.1804 | <0.0001 | -10.8607 | 2.6421 | <0.0001 | -14.8182 | 4.4554 | 0.0009 |
| φ | 15.6120 | 3.5320 | <0.0001 | - | - | - | - | - | - |
| AIC | -63.2794 | -61.7153 | -64.5549 | ||||||
| BIC | -55.0915 | -55.1649 | -58.0045 | ||||||
The information criteria, AIC and BIC statistics, are used to select the best model for the data used. Since the lowest values of the AIC and BIC statistics are belong to the log-Bilal regression model, we conclude that it is best by comparison with the beta and unit-Lindley regression models. Additionally, the residual analysis is done to evaluate the suitability of the fitted models for the data used. Fig 5 displays the quantile-quantile plots of the randomized quantile residuals. As seen from these figures, all fitted regression models provide adequate fits, but, the plotted points for the log-Bilal regression model are more closer the diagonal line than the beta and unit-Lindley regression models.
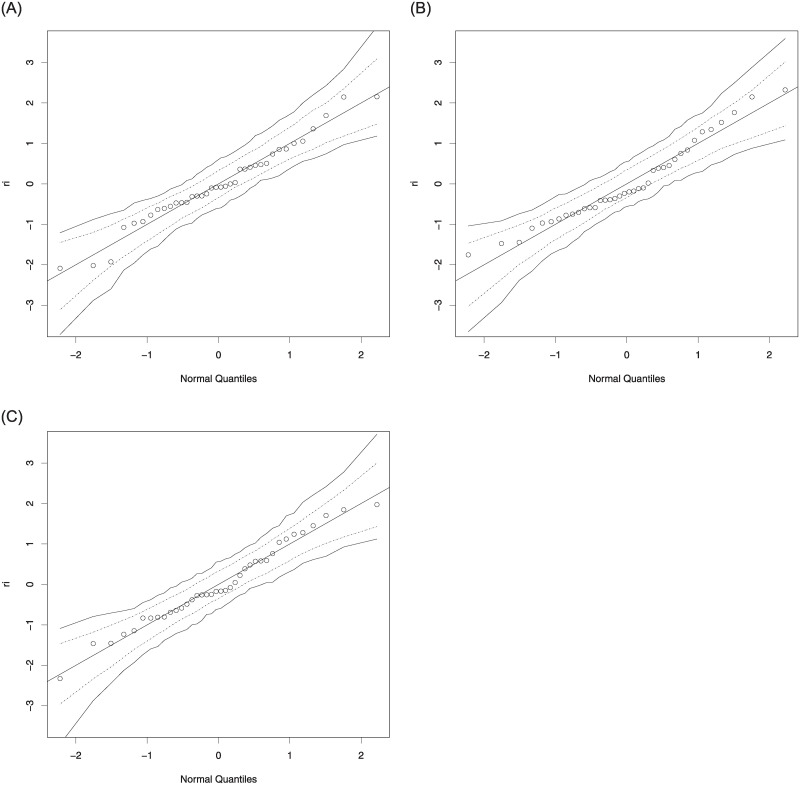
The quantile-quantile plots of the randomized quantile residuals: Beta (left), unit-Lindley (middle) and log-Bilal (right).
7 Conclusion
For the first time, a new one-parameter unit distribution is introduced for modeling the extremely left-skewed data sets measured in unit-interval. The new model provides a reasonably better fit than the other one and two-parameter unit distributions such as Topp-Leone, unit-Lindley, Kumaraswamy, and beta distributions when the data sets are extremely skewed to left (right). The newly defined regression model is compared with the famous beta regression model as well as the recently proposed unit-Lindley regression model. The results of the data analysis show that the proposed models work better than other existing models. As a future work of the presented study, we plan to introduce the quantile regression model based on the log-Bilal distribution. Additionally, we extend our model for modeling the longitudinal data sets as an alternative to the longitudinal beta regression model.
Appendix
Beta distribution:
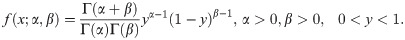
Kumaraswamy distribution:
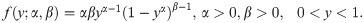
Topp-Leone distribution:
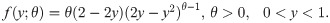
Unit-Lindley distribution:
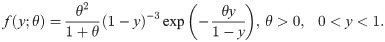
References
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17