
The authors have declared that no competing interests exist.
Many ecological studies employ general models that can feature an arbitrary number of populations. A critical requirement imposed on such models is clone consistency: If the individuals from two populations are indistinguishable, joining these populations into one shall not affect the outcome of the model. Otherwise a model produces different outcomes for the same scenario. Using functional analysis, we comprehensively characterize all clone-consistent models: We prove that they are necessarily composed from basic building blocks, namely linear combinations of parameters and abundances. These strong constraints enable a straightforward validation of model consistency. Although clone consistency can always be achieved with sufficient assumptions, we argue that it is important to explicitly name and consider the assumptions made: They may not be justified or limit the applicability of models and the generality of the results obtained with them. Moreover, our insights facilitate building new clone-consistent models, which we illustrate for a data-driven model of microbial communities. Finally, our insights point to new relevant forms of general models for theoretical ecology. Our framework thus provides a systematic way of comprehending ecological models, which can guide a wide range of studies.
Mathematical models of population dynamics are an important tool to advance our understanding of ecosystems, which can be relevant for environmental, clinical, and industrial applications. One sanity check for such models is to virtually split a population into two with identical properties – allegorically, we paint half the individuals of the population in a different color. As we do not change the ecological situation, the outcome of the model should not change either; we call this feature clone consistency. We investigated the mathematical properties of clone-consistent models and deduced simple rules for their form. These rules allow to easily check clone consistency in existing models and ensure it when building new ones. The resulting framework can guide researchers in building models for specific ecosystems and in investigating general properties of ecosystems. We showcase our approach by applying it to models for bacterial communities causing urinary-tract infections. We further discuss that clone inconsistency, which occurs in several prominent models, reflects strong, often implicit, assumptions and it is important to check whether these are justified. Such assumptions may diminish the applicability of these models and the generality of results obtained with them.
This is a PLOS Computational Biology Methods paper.
Many theoretical and semi-empirical studies of ecological communities employ general models that are not specific to a given community, but can incorporate an arbitrary number of populations with different properties [1–4]. In most such models, the equations governing each population have the same form, and the species of a population only manifests in the values of the associated parameters. These parameters may describe the properties of a single population, the interaction of two populations, or higher-order interactions, i.e. effects involving three or more populations [5, 6]. Interaction parameters are often chosen randomly [7–13] or determined from experiment [14–17].
Developing such models is one of the challenges of modern ecology, in particular when incorporating empirical data [18]. For example, recent advances in automating experiments have enabled measuring interaction parameters for richer communities [16, 19–21], interactions characterized by more than one observable [16], or higher-order interactions [15, 22]. These new experimental scenarios call for new ecological models that can incorporate the respective data. Existing models are often not suitable here since there is no uniform answer as to how multi-parameter or higher-order interactions should be measured [3, 6, 16, 20, 23]. Another driver of new modeling approaches is growing computational power [18, 24], which allows to investigate increasingly general and complex models [12, 25].
To improve the modeling process, several collections of criteria capturing consistency were suggested [26–34]. While many of these are specific to the ecological scenario considered, e.g., predation, the following invariance is a recurring theme [28–38]: If two populations have identical parameter values, they contain identical individuals (clones) within a general model. Thus, the outcome of the model must only depend on the total abundance of these two populations, and not on how the clones are assigned to them. We call this criterion clone consistency. Similar criteria for models have been named invariance under relabeling [32] or under identification/aggregation of identical species [29–31] as well as “common-sense” condition [34, 36, 38]. Further, it is often required that joining two populations of identical individuals does not affect diversity measures and other ecological observables [39–41]; this concept was introduced under the name twin property [42]. In the analysis and modeling of food webs, this issue is essentially circumvented by considering trophic species, which aggregate species with identical predators or prey – a controversial approach [43–47]. Finally, if a model is clone-consistent and clones actually exist, it can be simplified; this is called aggregating or lumping [48, 49].
To provide an instructive example for clone inconsistency, we compare two simulations of a predator–prey scenario using the same general model [51] (chosen here exclusively for its simplicity):
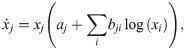
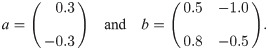
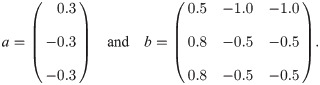

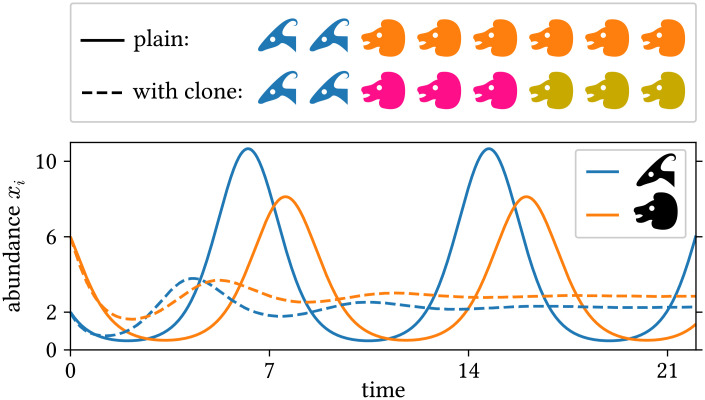
Example of clone inconsistency: Two simulations of a simple predator–prey scenario using the same general model (see text for details).
Solid lines: simulation using one population for prey (blue, antelopes) and predators (orange, lions) each. The initial abundances are x1(0) = 2 and x2(0) = 6 (animal heads in the top legend). Dashed lines: same, but with two identical predator sub-populations (pink and ocher) with half the initial abundance; the abundance shown for the predators is the sum over the two sub-populations. The simulations were run with JiTCODE [51] using the DoPri5 method (S1 Code).
While splitting populations is an illustrative thought experiment, its implications reach farther for at least three reasons: First, in actual modeling we can encounter the inverse situation, i.e., two populations with identical properties. Second, if there are problems when two populations have absolutely identical properties, there will also be problems when they have similar properties since models, like nature, are continuous. Third, problems can already arise if two populations are similar in one aspect that is relevant to the model. In a variation of the above example, if the members of two populations of predators prey with a similar rate on a given focal species, assigning individual predators to the other population should not disproportionately affect the total predation rate – even when these predators reproduce at different rates.
Despite its simplicity, ensuring clone consistency directly can be tedious as it requires finding a counter-example or performing a model-specific proof. For example, Morozov and Petrovskii [33] spent several pages of calculations on checking a weaker criterion for a handful of models. Several proposed models [3, 16, 50, 52–63] are not clone-consistent (see Implications for details).
Here, we present a framework for checking and ensuring clone consistency in models. This paper is structured as follows: In What models are clone-consistent?, we introduce basic concepts and criteria on which we then build our framework employing methods from functional analysis. We explain how to use this framework to systematically assess and build models. In Case Study, we demonstrate the features of our framework by applying it to a recent model for microbial communities. In Implications, we discuss the consequences of our results. In particular, we explain how specific assumptions may fix an apparent clone-inconsistency. Our framework guides modellers by forcing them to make such assumptions explicit, which automatically raises the question if they are justified. Moreover, we discuss how our framework applies to all models involving multiple populations and its general implications for ecological modeling studies. In Methods, we provide elaborations and proofs for the mathematically inclined reader.
In this section, we first define impact functions, which are fundamental ingredients of ecosystem models that allow us to mathematically encode our consistency criteria. We then expose the consequences of our consistency criteria – first for impact functions and then for entire models. In particular, we present recipes for checking and building models.
Impact functions describe the impact of a community on a species, on a resource, or on any other relevant feature of the ecosystem that is captured in a model. Features and phenomena described by impact functions include:
the effective growth rate of a given species,
the remaining size of a niche,
the rate of predation,
the availability of a resource or, if the resource is a dynamical variable, its consumption and production,
reproductive services, e.g. pollination,
the amount of crowding, and
general interaction terms, e.g. the sum in the generalized Lotka–Volterra model [1].
The arguments of impact functions are the abundances of all populations in the ecosystem x = (x1, x2, …, xn) and parameters a = (a1, a2, …, an) that quantify the impact of the populations. Often the impact of a population i is described by a single number. Yet our results also hold for the more general case that m parameters per population are required, i.e., .
A prominent example of an impact function is:
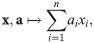
We require impact functions to fulfill the following basic criteria (illustrated in Fig 2; see Methods, The functional algebra of impact functions for mathematical formulations):
I1 Commutativity: The properties and idiosyncrasies of a given population are exclusively captured by its associated parameters, as opposed to dedicated mathematical terms in the function. This is equivalent to pairs of abundances and parameters ((xi, ai)) being interchangeable as arguments of the impact function.
I2 When a population is absent, its associated parameters have no effect on the value of the impact function.
I3 When each parameter associated with a given population is zero, that population’s abundance has no effect on the value of the impact function.
I4 Clone consistency: If two (or more) populations have identical parameters, the value of the impact function must only depend on their summed abundance and not on its distribution among the two populations.
Note that this criterion is a special case of clone consistency as described in the introduction. Using impact functions complying with this criterion is therefore necessary for a model to be clone-consistent, but not sufficient (we will address clone consistency on the scope of the entire model later). Due to the narrower scope of this criterion, the populations do not need to be identical in all respects, but only in the parameter(s) used by the respective impact function.
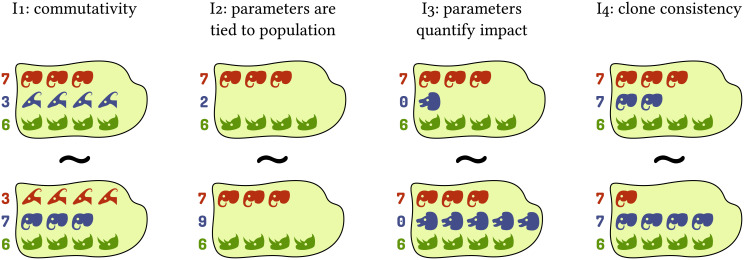
Criteria for impact functions exemplified for the grazing impact of animal populations.
Each island represents a community. Each row and color represents one population in the model, with animal heads representing individuals. Numbers on the left represent parameters governing the respective population (grazing rate in the example), and head shapes indicate whether populations have identical properties as per these parameters. The similar sign (∼) indicates that two communities are equivalent as arguments of an impact function, i.e., they should yield the same result (total amount of grazing in the example).
Note that it is often reasonable to choose a considerable portion of parameters to be zero. For example, if our impact function describes predation loss of a given focal species, we would choose ai = 0 for all populations i that do not prey upon the focal species. In the following we call a function impact function if and only if it satisfies these criteria.
While the criteria I1–I4 for impact functions are conceptually simple, it is not straightforward to test directly if a given function complies with them or to devise a new function that does. To address this issue, we investigated the functional form of impact functions and found a set Ω of basic impact functions, which can serve as building blocks for ecosystem models.
These basic impact functions are linear combinations of abundances and (potentially transformed) parameters, i.e., all functions of the form:
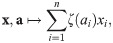
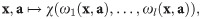
To illustrate the composition of impact functions from these building blocks, we consider the case of a single population of flowering plants that may be both pollinated and grazed upon by several insect populations [64] as a toy example (also see Fig 3, bottom). We use a function ρgraz to describe the rate at which insects (and their larvae) graze on the plants:
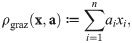
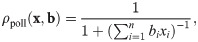
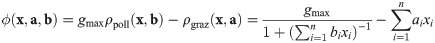

Recipes for building and validating models using our framework.
In general xi denotes the abundance of population i, and ai, bi, ci, and di are parameters describing its impact. The example for checking is based upon Eq 21 and tailored for covering relevant cases. The example for building extends the one from The form of impact functions. For both examples, the biological background is discussed in more detail in the main text.
Our treatment of impact functions allows us to ensure clone consistency when modeling the effects of a community. To ensure clone consistency of an entire population model, we additionally need to require clone consistency when modeling the effects on the growth of a population. Specifically, we require that the total growth of two populations of identical individuals must be the same as if those two populations were joined in the model.
We consider models of the forms:
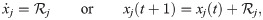
We proved that must have the form (see Methods, Non-impact-function contribution to abundance changes must be proportional):
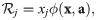
This insight provides an easy way to verify if models comply with our consistency criteria. We simply need to check if they have the form of Eq 11. To verify in turn if ϕ is an impact function, we can look for terms of the form of Eq 5. For instance, a common formulation of the generalized Lotka–Volterra model [1] can be rewritten as:
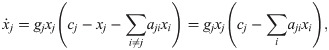
This recipe can be inverted to build a clone-consistent model. In the example from The form of impact functions, we can directly insert Eq 9 into Eq 11 and obtain a model for the change of a plant population in light of pollination and grazing (see Fig 3 bottom). If we stringently apply our framework here, the only thing that distinguishes plants and insects is that the former have a grazing and pollination rate of zero.
Our framework can also be applied to experiments that do not assess the details of ecological interactions (nutrients, toxins, etc.) but only aggregated, phenomenological interaction observables, such as the carrying capacity of a population in the presence of another. This is typical for high-throughput experiments assessing the pair-wise interactions of microbial communities [15, 16, 19–22]. Combining Eqs 10, 11, 6, and 5, we obtain a general ansatz for such a model:
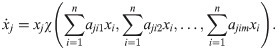
Here, we refrain from transforming the parameters (corresponding to ζ = id in Eq 5), since this would not affect the final model. First we identify the number of basic impact functions m as the number of interaction observables: Using fewer than m basic impact functions would entail that interaction observables would go unused, i.e. available information on the system would be ignored; more than m basic impact functions would make the model overly complex given our limited knowledge of the system. The choice of the combining function χ depends on the application, but we expect that a product of transformations of individual basic impact functions is often appropriate. In this case our ansatz becomes:
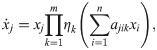
the requirement that the model should reproduce key characteristics of the experimental scenarios, e.g., the carrying capacity of a population,
ecological assumptions and facts about the scenario, e.g., that the predation rate should increase with the abundance of predators, or
assumptions of simplicity (Occam’s razor), e.g., that ηk should not be more complex than necessary to fulfill the experimental and ecological constraints.
In New model, we provide an example for this approach.
Our framework is readily extended to models describing second- or higher-order interactions. For this, one simply has to consider parameters that are associated with more than one population. Then, it is convenient to use other basic building blocks (instead of Eq 5), for example for second-order interactions:
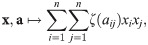
As an instructive example, we apply the impact-function framework to describe the dynamics of a microbial community for which multiple ecological interaction observables were recently measured experimentally. We first describe the experiment and the general modeling challenge. Then we show that an existing model is clone-inconsistent and discuss the specific reasons and implications of this. Finally, we show how our framework can be used to build a new clone-consistent model.
A recent study (co-authored by one of us) used a high-throughput approach to systematically measure ecological interactions in microbial communities consisting of strains isolated from polymicrobial urinary-tract infections (UTI) [16]. For each strain, the exponential growth rate gj and the carrying capacity cj in isolation were measured (Fig 4, left). For convenience, abundances of each strain j were normalized such that cj = 1. Furthermore, for each strain k, a medium partially conditioned by that strain was produced (it contains a fraction v of the supernatant). In each such partially conditioned medium, the conditioned growth rate gjk and carrying capacity cjk of each strain j were measured to quantify how strain k affects strain j (Fig 4, right). Creating a model from this dataset is particularly challenging since it has to include two interaction observables: growth rate and carrying capacity in conditioned medium.

Acquisition of data used in our case study.
Measurement of growth characteristics (left) and pairwise interactions (right) of bacterial strains isolated from urinary-tract infections [16]. Left: Each strain j was cultivated for 48 h in artificial urine. Solid bold letters represent individuals of the respective strain. The exponential growth rate gj as well as the carrying capacity cj (named yield in the original study [16]) were experimentally determined via optical densities. Right: For each strain k, a conditioned medium was produced by letting the strain grow for 48 h, mechanically removing the bacteria to obtain a supernatant, and mixing the result with fresh medium in a ratio of v ≔ 0.4. Outline letters (“footprints”) indicate to what extent the respective culture consists of supernatant. In each such medium, each strain j was cultivated, and the conditioned growth rate gjk and carrying capacity cjk were determined as above.
For modeling this system, it is a plausible assumption that the abundance of a population also represents its footprint, i.e. the nutrients, toxins, and other relevant substances produced or depleted by that population. The basis for this simplifying assumption is that populations are declining only due to dilution of the entire system, which has the same effect on the footprint. With this assumption, we can treat the medium partially conditioned by strain k as an ecosystem where the abundance of that strain is fixed to the corresponding fraction of its carrying capacity (xk = vck = v).
The general form of an ordinary differential equation describing the (normalized) abundance xj of population j in this system is . Such models should reproduce the observed growth rates and carrying capacities for all situations that were experimentally investigated. For instance, in the absence of other strains, the initial exponential growth rate of strain j in the model should be equal to its experimentally observed exponential growth rate gj:
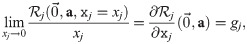
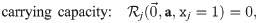
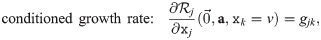
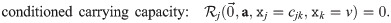
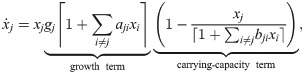
The original study [16] proposed a model for communities consisting of such strains based on Verhulst’s logistic model for one population [65]:
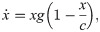
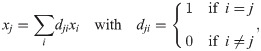
The fixed points of this model are characterized by:
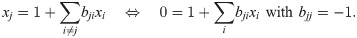
We use our framework to construct a new population dynamics model for this scenario. Since two experimental interaction observables are available, we make an ansatz using two basic impact functions (see Assessing and building models). As one of the observables and thus one of the impact functions captures the carrying capacity, we choose to multiply (and not add) the impact functions to ensure that an impact function can single-handedly reduce the growth to zero. Our ansatz is thus Eq 14 with m = 2:
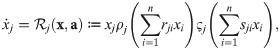
Inserting this ansatz into Eqs 16–19 and making a few choices that do not affect generality already yields strong constraints on the functions ρj and ςj and on how the parameters rjk and sjk relate to these and the experimental parameters gj, gjk and cjk, namely (see Methods, Deriving a new model for UTI strains – the legwork):
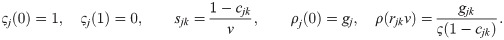
By further making simple choices for ρj and ςj within these constraints and accounting for singularities and discontinuities (see Methods, Deriving a new model for UTI strains – the legwork), we arrive at the following model (with ⌈z⌉ ≔ max(0, z)):
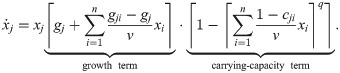
Like the existing model (Eq 21), this can be understood as an expansion of Verhulst’s logistic model with the following differences: First and foremost, the carrying-capacity term is simplified to achieve clone consistency – interactions affecting the carrying capacity of population j are now captured in a single sum. Second, the additional parameter q governs how abruptly the saturation effect kicks in. Third, the dilution factor v is included consistently without case distinctions. Fourth, as per the initial assumptions, populations cannot decline anymore (unless dilution is added to the model). The particular form of this model illustrates how challenging it can be to write down clone-consistent models from scratch without using the framework presented here.
We find that this model can explain observed species abundances and ecological stability in a small experimental dataset (S1 Appendix) at least as well as the previous model (Eq 21). Moreover, the fixed points of both models are the same under most conditions (S1 Appendix).
While many popular models, including most variants of the generalized Lotka–Volterra model [1], comply with our criteria, others do not [50, 52: Eqs 9 and 10, 53, 54: Eqs 1.28–1.30 and 1.50, 55: Eqs 11 and 12, 56, 57, 58: Eq 5, 59: NFR model, 60, 16, 61, 62: Eq 3, 3: Figs 3b and c, 63: UIM and IIM model]. However, as we will elaborate below, this does not mean that these models should be dismissed outright.
Any model can be made clone-consistent by setting the right parameters to zero (Fig 3 and Eq 22). For instance, suppose that u − xj quantifies the unoccupied portion of the niche of population j. We can extend this term to an impact function:
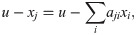
As an instructive example, consider a recently proposed unique-interactions model (UIM) [63]. This model features three interaction terms. Two describe the influence of mutualistic or exploitative interactions, respectively, on a focal population j as:
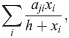
A similar case of assumptions justifying clone inconsistency arises if some features of populations cannot be feasibly encoded in numerical parameters, which we assumed as given so far. For example, compatibility for sexual reproduction is tedious to capture in a parameter; instead, it is often reasonable to assume that populations do not interbreed (i.e., contain species as defined by Mayr). In this case, splitting a population in two equal parts also halves the availability of partners for sexual reproduction. Thus, this availability should not be described by a clone-consistent impact function. These examples illustrates how clone-inconsistent terms can make sense in a model if properly justified.
Many of the aforementioned studies based on clone-inconsistent models primarily make statements about the effects of model properties on population dynamics. If these findings are based on strong assumptions, their generality, relevance, and applicability are considerably diminished. Moreover, if these assumptions are implicit, this increases the risk that the study is misinterpreted and misapplied by others. The framework presented here will help to avoid these problems by forcing key assumptions of ecological models to be explicitly stated and justified.
Our approach extends to diverse types of models. In particular, it is not restricted to models employing ordinary differential equations, but also applicable to models with noise, time delays, or discrete time steps. Further, higher-order interactions are covered by our framework. We mainly used impact functions to describe the impact of a community on a population. However, both the target and the source can be other entities, e.g. the availability of a resource, the concentration of a toxin, or an aggregated observable such as the albedo of foliage or the pH value of a growth medium. A common case is the impact of the community on a resource within a consumer–resource model [66, 67]. Going beyond modeling, impact functions that describe observables are closely linked to the requirement for ecological observables – such as diversity – to be clone-consistent [39–41].
Notably, the framework presented here has conceptual parallels to pharmacological approaches that are widely used as null models for the combined effect of two drugs [68, 69]: One is Loewe additivity, which is based on arguments similar to clone consistency and is a suitable reference if the two drugs target the same component of the cell. The other is Bliss independence, which violates clone consistency at first glance and is suitable if the two drugs affect different components of the cell. In our framework, drugs that target the same cell component correspond to using the same interaction mechanism and thus would be captured by the same basic impact function. The effect of a complex drug cocktail could be captured by several Bliss-independent basic impact functions, each of which comprises a series of Loewe-additive components.
While each instance of unjustified clone inconsistency reflects a shortcoming of the model, general statements about the consequences of clone inconsistency for the solutions of a model are most likely impossible. Clone inconsistency is tightly intertwined with the fabric of the model, and thus we cannot study its effect in isolation. Moreover, there is no reason to expect that clone-inconsistent models have any relevant commonalities, as they are extremely diverse. For example, it makes a difference whether joining identical populations increases or decreases some impact (that would be unchanged in a clone-consistent model). For illustration, the diversity of clone-inconsistent models may be compared to that of all numbers not divisible by seven. Similarly, it is likely not possible to draw general conclusions about the dynamic behavior of the clone-consistent models – such as favoring or suppressing oscillatory dynamics. While they are based on linear combinations, they can certainly be non-linear. Not only can a non-linear function still be applied to the linear combination (e.g., χ in Eq 6), but any existing non-linear model can be made clone-consistent by sufficiently strong assumptions. The central question is whether these assumptions are biologically justified. However, insights can be gained by interpreting each impact function as a mechanism of ecological interaction:
Many pure modeling studies use a model of the general form [12, 59, 62]:
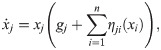
To fill this gap, our framework suggests an alternative form for general ecosystem models, such as:
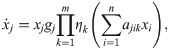
We introduced a framework for building ecosystem models using impact functions as building blocks. This framework is aimed at ensuring the clone consistency of models and thus constrains the possible choices of models. While at first this may seem like at a burden, we anticipate that it will rather facilitate the modeling process by guiding ecologists when choosing from the (still infinitely many) clone-consistent models. Our framework further prompts relevant questions about the underlying assumptions of models. Specifically, the absence of impact functions in a model exposes that it is clone-inconsistent, which may indicate a fundamental problem. Alternatively, clone-inconsistency can reveal implicit assumptions at the heart of the model, which need to be justified and may limit the model’s generality. Our framework also informs the form of more general models by outlining the space of possible models for ecosystems and enables new research directions in this field. Finally, our approach could be extended to implement criteria for specific ecological scenarios such as predation [27–30, 33]. Overall, the framework presented here provides a systematic way to understand models and can form the backbone for a wide range of ecological modeling studies.
lowercase italic letters: numbers or parameter configurations (tuples of numbers);
lowercase Greek letters: functions;
boldface letters: vectors or similar;
uppercase letters: sets of respective contents;
n: the number of populations;
m: the number of parameters per population;
: the non-negative real numbers;
: the space of all possible population abundances;
: the space of all possible parameter configurations of these populations;
X × A: the domain of impact functions;
x = (x1, …, xn) ∈ X: an arbitrary first argument of an impact function (abundances), where xi is the abundance of population i;
a = (a1, …, an) ∈ A: an arbitrary second argument of an impact function (parameters), where are the parameter values that describe population i;
non-italic sans-serif letters: modifications of specific components of arguments of an impact function (similar to named arguments in many programming languages). For example: ϕ(x, a, x2 = y) denotes ϕ((x1, y, x3, …, xn), (a1, …, an)). Here the arguments of the function φ are x and a except for the abundance of the second population (x2) being changed to y.
: the function that maps to (anonymous function).
: is defined as .
Proof: Ξ generates Φ requires additional notation that is mostly introduced in that subsection.
In this subsection, we describe our main mathematical result and connect it to the main text, from encoding our criteria mathematically to translating the results back to application.
Expressed in equations, our criteria for impact functions are:
I1 Commutativity:
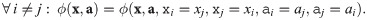
I2 When a population is absent, its associated parameters have no effect:
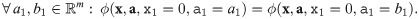
I3 When all parameters associated with a given population are zero, that population has no impact:
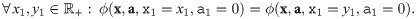
Note that the parameter value corresponding to no impact could be readily changed from zero to any other value.
I4 Clone consistency:
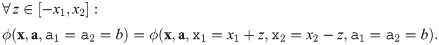
Note that through commutativity (I1), the other criteria apply to all populations or pairs of populations of the impact function ϕ, respectively (and not just to populations 1 and 2). Clone consistency (I4) of more than two populations is covered by applying the respective criterion repeatedly.
In the terms of functional analysis, impact functions form a functional algebra Φ. This means that each product or sum of two impact functions is again an impact function and that each multiple of an impact function is an impact function. This algebra is also closed, which means that the limit of uniformly converging sequences of impact functions is again an impact function.
To easily build and detect impact functions, it is crucial to find a (small) set of impact functions from which all impact functions can be build, i.e., a generating set of Φ. Our main mathematical result is that Ξ = Λ ∪ Γ is such a generating set, where Γ is the set of constant functions and taking the limit of a uniformly converging sequence is considered amongst the generating operations. Λ is the set of all linear combinations of powers of parameters and abundances, i.e., functions of the form:
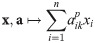
We will formally prove this in the next subsection (Proof: Ξ generates Φ), but the essential idea is this: Our criteria (I1–I4) require an impact function to have the same value on given subsets of its domain. For Ξ to be a generating set of Φ, it must reflect this: First, the functions in Ξ must be constant on each such subset, i.e., fulfill our criteria for impact functions. Otherwise Ξ would also generate functions that are not impact functions. (It is straightforward to show that the elements of Ξ fulfill our criteria, however, in our proof this is a by-product.) Second and more crucially, for each pair of points that are not in the same subset, there must be a function in Ξ that differs between these points (this is called separating points). Otherwise some impact functions could not be generated by Ξ. We show the latter by using our criteria (I1–I4) to systematically transform arguments of impact functions to a canonical form, in which populations are ordered by impact and maximally lumped together.
In application, the fact that Φ is a closed functional algebra, i.e., that limits remain within it, is relevant as it addresses the case of a (non-polynomial, continuous) function being applied to the result of an entire impact function or the parameters. We can rewrite:
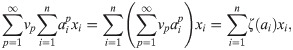
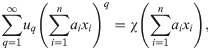
We here state and prove our main mathematical result, namely:
Theorem 1. Let denote the set of linear combinations of powers of values of the k-th parameter and abundances. Denote the set of all such functions as . Let Ξ ≔ Λ ∪ Γ, where Γ is the set of constant functions. Let Ψ be the generated set of Ξ, i.e., the smallest closed functional algebra that contains Ξ. Then Ψ = Φ, i.e., Φ contains all impact functions as characterized by criteria I1–I4.
To prove it, we apply Bishop’s Theorem [70, 71]. We here only need the reduction to the special case of real-valued functions (as opposed to complex-valued functions):
Bishop’s Theorem. Let Z be a compact Hausdorff space. Let Ψ be a closed unital subalgebra of . Let . Suppose that ϕ|S is constant for each subset S ∈ Z such that ψ|S is constant for all ψ ∈ Ψ. Then ϕ ∈ Ψ.
The requirements of Bishop’s Theorem on Ψ are fulfilled since Z can be any sufficiently large compact subset of X × A and the inclusion of Γ ensures unitality. To show that the functional algebra Ψ contains all impact functions, we therefore need to show that for an arbitrary impact function ϕ for any and :
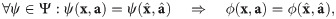
We prove that Λ separates points for m = 1 with three lemmas, for which we transform the arguments to a canonical form (Definitions 1–4), in which populations are ordered by impact and maximally lumped together. We first show that if all functions from Λ have the same value for two arguments, these arguments have the same canonical form (Lemma 1). We then employ our criteria to show that no impact function will differ for two arguments that have the same canonical form (Lemma 2). Finally, we combine the first two lemmas to show that if all functions from Λ have the same value for two arguments, so do all impact functions (Lemma 3). Thus Λ separates points where it needs to (as per Eq 38).
Definition 1. Let x ∈ X and a ∈ A. Let be the ordered sequence of non-zero values of a that correspond to a non-zero abundance, i.e.:
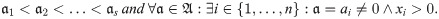
As the are unique and ordered, we will directly use them like indices to avoid additional levels of indexing. One can think of them as equivalence classes of parameters.
Definition 2. Let x ∈ X and a ∈ A. For a given , let be the set of indices where this parameter value is assumed and the corresponding abundance is not zero, i.e., the maximal set I such that and xi > 0 for all . Consequentially, for .
Definition 3. Let x ∈ X and a ∈ A. Denote the sums of abundances for one absolute parameter value as .
Lemma 1. Suppose and are such that:
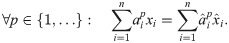
Then:
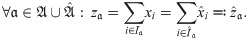
We show Eq 41 by induction over in descending order of absolute value. We first note that the lemma trivially holds for all . In the following we show that, if the lemma holds for all with , it also holds for and . (If one of and is empty, this does not affect this part of the proof.) To this end, we first show that the linear combinations must also be equal when only considering coefficients with (for all p):
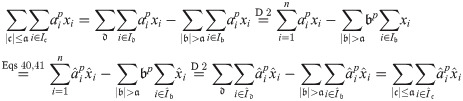
If and the above equality will be dominated by for p → ∞, which gives us:
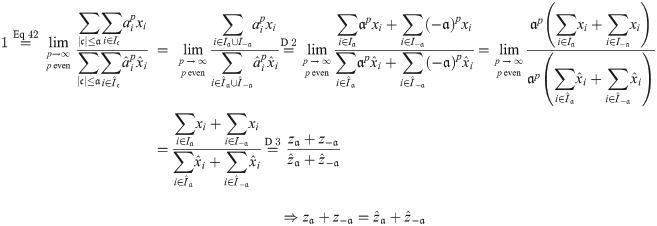
If exactly one of and were zero, the above limit would evaluate as either 0 or ∞ instead of 1; hence this cannot be. If both are zero, Eq 43 holds without further ado. Analogously, we obtain:
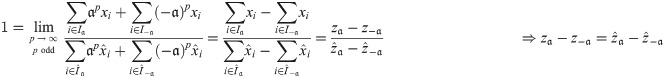
Definition 4 Define the canonical form of x ∈ X and a ∈ A as:
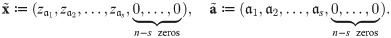
Lemma 2 Let x ∈ X and a ∈ A and ϕ be an impact function. Then .
We first transform blocks of arguments to the canonical form (with some zero arguments added if necessary) step by step, and show that the value of an impact function is not affected by these transformations. The first kind of block we consider are blocks of equal non-zero parameters and corresponding non-zero abundances, i.e., for some . Then, for some :
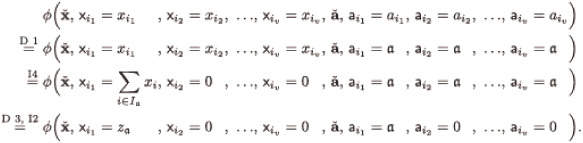
If a parameter ai or abundance xi, respectively, is zero, we transform the single-index block {i} to zero (for some ):
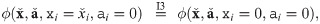
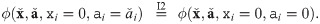
Second, after all blocks are transformed, we swap abundances and parameters in parallel to match the order in the canonical form. This does not affect the value of the impact function ϕ as it is commutative (I1).
Lemma 3 Suppose and are such that:
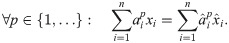
Let ϕ be an impact function. Then .
To prove this, we only need to note how the canonical forms and only depend on the parameters values corresponding to non-zero total abundance and these abundances. Those in turn are equal per Lemma 1. Thus:
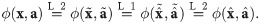
Here, we show that as defined in Eq 10 must have the form , where ϕj is an impact function. To keep the notation simple, we assume that features no delay, noise, explicit time dependency, or similar, and thus .
We require every impact of population other than j to be comprised in an impact function ψj. We can write in the form:
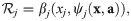
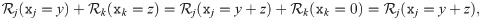
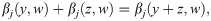
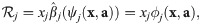
We here elaborate the details of creating a new model for the case described in Case Study.
Inserting our ansatz (Eq 24) into our first requirement (Eq 17), we obtain:
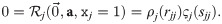
Assuming that the two factors do not “take turns” in being zero for different j, this means that either ρj(rjj) = 0 or ςj(sjj) = 0. Without loss of generality, we assume that the latter applies, thus assigning ςj the role of quantifying the carrying capacity. Furthermore, we choose ςj(0) = 1. These are normalization choices, as they can be compensated by including a respective factor in ςj or ρj respectively. Using this and expanding Eq 19, we obtain:
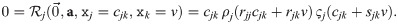
Assuming that ςj is again responsible for the product being zero and it has only one root, namely 1, we arrive at: cjk + sjk v = 1, and thus: . Note that since sjj = 1, this is consistent with our choice of cjj = 1 − v (see S1 Appendix).
Using the above, we can expand Eqs 16 and 18:
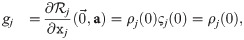
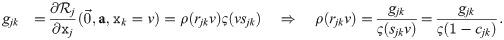
We choose the arguably simplest function to fulfill the criteria for ρ, namely ρj(z) ≔ gj + z. This has the consequence:
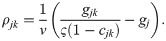
A group of functions fulfilling the criteria for ς is: ςj(z) ≔ 1 − ⌈z⌉q with q > 0 and ⌈z⌉ ≔ max(0, z). Here, the free parameter q controls how early and smoothly the saturation effect of a occupied niche kicks in. Note that this choice results in terms similar to what was named hyperlogistic [72].
Finally, like the original study [16], we constrain the growth and capacity term to be non-negative to avoid the occasional implausible result. For example, we do not allow negative growth because we equate the abundance of a population with its footprint, which cannot be undone, and we lack the data to capture cell death. Putting everything together, we arrive at the model:
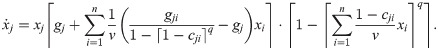
A problem with this model is that for 0 < xk < 1, we have: . Now, cjk = 0 means that there is no growth of strain j in the medium conditioned by strain k and thus we already have a problem with experimentally determining gjk. Thus, one might argue that the actual point of the singularity requires a dedicated case distinction anyway. However, also means that becomes arbitrarily large for small cjk. A way to address this problem is to consider the case q → ∞, or more specifically:
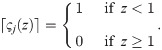
In our simulations, we therefore make a trade-off between complying with Eq 18 and the numerical benefits of a continuously differentiable model by setting q = 10 and approximating ς(1 − cjk) ≈ limp→∞ ς(1 − cjk) = 1 in Eq 58, thus arriving at:
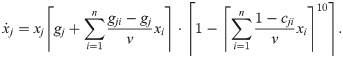
We are grateful to H. Arndt, J. Aufdermauer, M. Cosentino-Lagomarsino, A. Espinosa-Cantú, U. Feudel, J. Freund, S. Khaiwal, Y. Mulla, G. Petrungaro, S. Vet, M. de Vos, J. Werner, and M. Zagorski for inspiring discussions or constructive comments on previous versions of the manuscript.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
 Building clone-consistent ecosystem models
Building clone-consistent ecosystem models
 Facebook
Facebook
 Twitter
Twitter
 Linkedin
Linkedin
 Whatsapp
Whatsapp

