
The authors have declared that no competing interests exist.
Collective behavior is an emergent property of numerous complex systems, from financial markets to cancer cells to predator-prey ecological systems. Characterizing modes of collective behavior is often done through human observation, training generative models, or other supervised learning techniques. Each of these cases requires knowledge of and a method for characterizing the macro-state(s) of the system. This presents a challenge for studying novel systems where there may be little prior knowledge. Here, we present a new unsupervised method of detecting emergent behavior in complex systems, and discerning between distinct collective behaviors. We require only metrics, d(1), d(2), defined on the set of agents, X, which measure agents’ nearness in variables of interest. We apply the method of diffusion maps to the systems (X, d(i)) to recover efficient embeddings of their interaction networks. Comparing these geometries, we formulate a measure of similarity between two networks, called the map alignment statistic (MAS). A large MAS is evidence that the two networks are codetermined in some fashion, indicating an emergent relationship between the metrics d(1) and d(2). Additionally, the form of the macro-scale organization is encoded in the covariances among the two sets of diffusion map components. Using these covariances we discern between different modes of collective behavior in a data-driven, unsupervised manner. This method is demonstrated on a synthetic flocking model as well as empirical fish schooling data. We show that our state classification subdivides the known behaviors of the school in a meaningful manner, leading to a finer description of the system’s behavior.
Many complex systems in society and nature exhibit collective behavior where individuals’ local interactions lead to system-wide organization. One challenge we face today is to identify and characterize these emergent behaviors, and here we have developed a new method for analyzing data from individuals, to detect when a given complex system is exhibiting system-wide organization. Importantly, our approach requires no prior knowledge of the fashion in which the collective behavior arises, or the macro-scale variables in which it manifests. We apply the new method to an agent-based model and empirical observations of fish schooling. While we have demonstrated the utility of our approach to biological systems, it can be applied widely to financial, medical, and technological systems for example.
Collective behavior is an emergent property of many complex systems in society and nature [1]. These behaviors range from the coordinated behaviors of fish schools, bird flocks, and animal herds [2–4], to human social dynamics such as those of traders in stock markets that have led to bubbles and crashes [5] in the past, and opinions on social networks [6]. Collective behavior amplifies the transfer of information between individuals and enables groups to solve problems which would be impossible for any single group member alone [7]. Furthermore, manifestations of collective behavior in both social and ecological systems regularly influence our individual welfare [8–10] through political and economic instability, disease spread, or changes in social norms. Building a better classification and understanding of collective behavior and collective states is crucial not only to basic science, but to designing a stable future.
A key challenge in the study of complex systems is to identify when collective behavior emerges, and in what way it manifests [11, 12]. Statistical physicists first studied emergence in complex systems in the 1800s where they began to derive the physical laws governing the macroscopic behavior of systems with an extremely large number of degrees of freedom from the interactions between the microscopic, atomistic components of the system. Remarkably, there usually exist a small number of macroscopic variables or order parameters that accurately describe macroscale dynamics for numerous systems, and a small number of relationships between these variables characterize the different states or behavioral regimes of the system. In many systems, the key macroscopic variables are well known from either first principles or empirical study: consider for example the organized and disorganized states of the flocking model in Fig 1. However, there are many social, ecological, and even physical systems which elude simple description by macroscopic variables [13–16]. Furthermore, we continually encounter novel systems for which we have no prior knowledge about multiscale dynamics, or models that give rise to unknown group dynamics [17]. In these cases, it is a non-trivial task to identify useful variables (at particular scales of organization) which define the possible emergent behaviors.

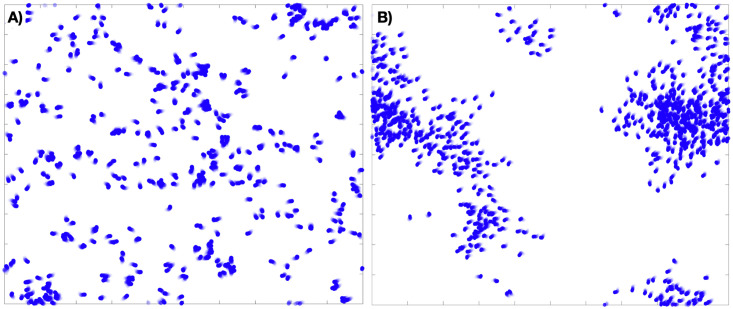
Examples of an 800 agent flocking model on the torus, with and without long-range order, that is, in both incoherent (A) and coherent (B) macro-states.
Machine learning and other statistical methods have emerged as key tools for finding macroscopic descriptions of complex systems with many degrees of freedom, in the physical, ecological, and social sciences. The application of these tools has been driven by high resolution observations of microscopic degrees of freedom (particularly in ecological and social systems), increases in computing power, and the development of new algorithmic tools. Dimensionality reduction, clustering algorithms, and other unsupervised learning algorithms have been particularly successful in discovering macroscopic variables and behavioral regimes from microscopic data on complex systems [18]. The paramagnetic/ferromagnetic phase transition in the classical, 2D Ising model has been discovered by algorithms ranging in complexity from principal component analysis to variational autoencoders [18–20]. However, more complex types of collective phenomenon, such as topological phases, have not been successfully identified using algorithms like PCA, which assume that the data has a linear structure. In these more difficult cases, algorithms which can detect nonlinear structures such as diffusion maps have shown much greater promise. For example, diffusion maps have been used to find the Kosterlitz-Thouless phase transition in the XY-model from condensed matter physics [21]. The success of machine learning algorithms for physical problems suggests that machine learning could be of great practical use for the study of collective phenomena in social and ecological systems, which are usually much less amenable to theoretical analysis, and for which there often exists a significant quantity of data at the individual level [22].
Here we have developed an approach to analyzing collective behavior in biological systems based on dimensional reduction tools from manifold learning [23], specifically diffusion maps [24]. Using diffusion maps to formulate multiple data-driven coordinate systems, we compare their large-scale structures to find latent global relationships between different variables observed at the level of individual agents. We call this the map alignment between the two coordinate systems. When two variables serve to globally organize the data along similar lines, their map alignment is high. One can easily calculate the expected alignment between unrelated and independent variables, so this gives us a test that detects a system’s emergent behaviors but requires no prior knowledge of them. Moreover, the ways in which the coordinates are correlated leave a signature for the relationship between the macro-scale structures, and one may use this to distinguish various system-wide behaviors. We apply this tool to modeled data produced from simulations of birds flocking, and to empirical data on the activity of fish in a school (see S1, S2 and S3 Movies for illustrations of these modeled and empirical data). Using the micro-scale data to cast the agents’ network of interaction into multiple geometries, each evolving over time, we both detect the emergence of macro-scale organization as well as perform a meaningful classification of distinct modes of organization, identifying the macro-scale states of the system. Importantly, this analysis is based purely on changes occurring at micro-scales, and makes no assumptions about which macro-scale variables are important. This means that for any novel system of study, where there is a paucity of knowledge regarding which macro-scale variable to measure and track, one could use this approach to classify and observe the dynamics of the system at different levels of organization.
We begin with the basic definitions required to construct a diffusion map (Table 1 below summarizes our notation). This requires a set of data points, X, and a metric on those points, d. The data may be composed of many observables, making each xk ∈ X a vector in a space of potentially very high dimension. Essentially we employ the algorithm in [25], with α = 1 and ϵ = 1. This involves
(i)constructing a similarity measure, K(xi, xj), between pairs of data points,
(ii)normalizing K to create a Laplacian operator on the data,
(iii)computing eigenvector-eigenvalue pairs {(ϕk, λk)} for the Laplacian, and
(iv)constructing the diffusion map .

| Symbol Reference | |
|---|---|
| data set | |
| n | number of data points |
| [k] | the set of integers 1, 2, …, k |
| micro-scale observable | |
| d(⋅, ⋅) | metric on X |
| D | pairwise distance matrix |
| A | affinity matrix |
| heat operator | |
| diffusion distance on X | |
| {ϕk} | eigenvectors of |
| {λk} | eigenvalues of |
| Φ(t, ⋅) | diffusion map at scale t |
| {ψk(t, ⋅)} | diffusion coordinates of Φ(t, ⋅) |
| ξi,j | inner product of and |
The choice of similarity measure in (i) is highly system-dependent, for agent-wise interactions may manifest themselves in many different ways and so require different metrics. In (ii), the choice of normalization in constructing is subtler, and based on a choice of Laplace operator; this is not sensitive to the data under observation, but rather reflects an assumption of Manifold Learning, that the data points of X are drawn from a manifold embedded in euclidean space. For rigorous results on when such a manifold exists for a given dataset, see [26].
Given n points X = {x1, …, xn}, we construct an n × n matrix of pairwise distances, D = (Di,j) ≔ (d(xi, xj)), associated to a metric d. Writing k(x) for the kth nearest neighbor (kNN) of x ∈ X, let K(x, y) be the gaussian kNN (GkNN) kernel defined by
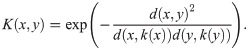
This kernel could be replaced with any other, as another function may better reflect the user’s impression of the similarity between two agents a distance d(x, y) apart. This particular choice is studied in [27], and serves to allow pairwise distances to scale according to their local geometries. One could consider this the standard gaussian kernel applied to the modified distance function . The more sparse the point cloud (X, d) is near x or y, the smaller this distance becomes. This kernel also has the desirable property that it is scale-free, in that multiplying all distances by a fixed constant does not change the kernel K.
Let σ denote a row sum operator: if A is an m × n matrix, let σ(A) be the m-vector whose ith component is . We next calculate an affinity matrix A = (Ai,j) ≔ (K(xi, xj)), its row sums σ(A), and construct the matrix operator A′ via
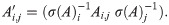
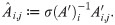
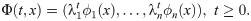
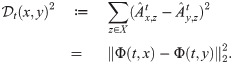
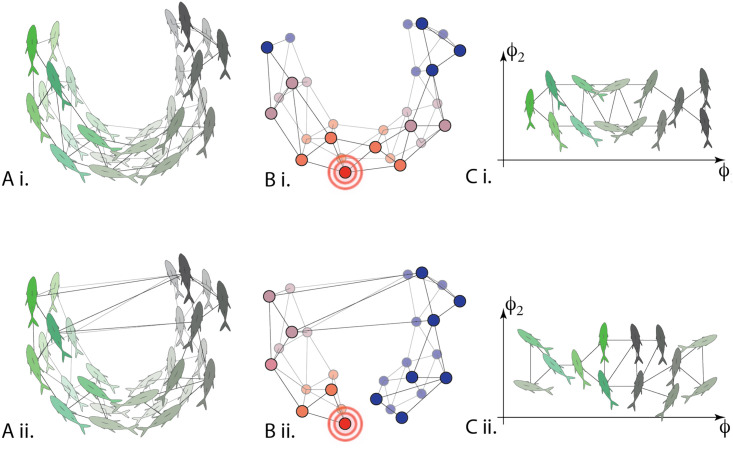
Conceptual illustration of diffusion maps applied to data on fish schooling.
A) For the same time period, different affinity operators can be calculated. These affinities could be correlations in simply spatial proximity (Ai) or correlations in velocities (Aii) for example. The operator is used to describe a network of agents. B) Once calculated, the heat diffusion operator allows us to quantify the geometry of the network and with this in hand C) diffusion map coordinates may be used to efficiently embed the fish in a low-dimensional space. Doing this for different metrics / affinities allows us to quantify the alignment between various diffusion map coordinate systems, which reveals changes in macro-scale behavior.
We remark that though increasing t decreases the resolution of small scale features in the embedding, in practice we take t = 1 throughout and define ψk(x) = λk ϕk, so that
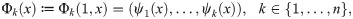
In this section we formulate a statistic to measure the degree to which the macro-scale organization of two observables measured on the micro-scale level are related. Let X = {x1, …, xn} be the collection of data for the n interacting agents making up the system, and let f1 and f2 be two vector-valued observables, such as position or velocity, defined on each agent,
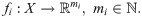
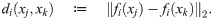
For each i = 1, 2 the diffusion coordinates are ordered by decreasing contribution to the global organization of the network X under the heat operator . Therefore if there is a coherent large-scale organization on X manifest in the observables fi, then the leading diffusion coordinates of Φ(1) should be determined in some manner by the leading coordinates of Φ(2). To confirm this, we expand the unit vectors in the subspace generated by the top k diffusion coordinates of , i.e. we project the eigenvectors into the subspace spanned by via the linear operator
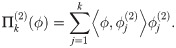
Then is a measure of how well the coordinate associated to f1 is correlated with the large-scale network structure induced on X by the variable f2. One attempts to choose k in a manner that ensures that the subspace spanned by encompasses the relevant macro-scale coordinates induced by f2 on X, but without k becoming so large that we begin to recover a significant portion of ϕ simply due to the large dimension of the image space. For example, if we take k = n the projection is the identity, simply expressing ϕ in the basis . However, taking k ≪ n we recover only the portion of the vector which can be expressed as a linear combination of the top k diffusion coordinates of Φ(2). We return to this issue below.
Now we derive the expected projection size under a null hypothesis that the two variables f1 and f2 are entirely unrelated. Given the pair of diffusion bases, we fix and calculate the distribution of the random variable assuming that the k-dimensional range, , is chosen uniformly at random from the set of all k-dimensional subspaces. One can show, and with a little thought it is clear, that this is equivalent to asking for the magnitude of a random unit vector of projected onto its leading k coordinates. When the vector is sampled uniformly at random from , the quantity is a beta distributed random variable with parameters (n −k)/2 and k/2. Recognizing this, one can calculate the expectation and variance to be k/n and 2(n − k)k/(n3 + 2n2), respectively. Normalizing the projection size accordingly, we arrive at the statistic
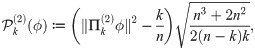
Again, the leading diffusion coordinates of Φ(i) are data-driven macro-scale variables, expressing the large-scale organization of the network as viewed through . If the data obeys a (possibly nonlinear and multi-valued) relationship between f1 and f2 on the macro-scale, then it should be evidenced by a relationship between the bases and . Note that the observables fi are used only in providing a metric on X. One can perform an identical analysis on the data given only the metrics d1 and d2. In the context of this paper we will assume, however, that the metrics come from some micro-scale variable defined on X, as this is the approach most useful in analyzing a new complex system.
Let be the vector of decreasing eigenvalues of , and take . Then the entries of give a normalized notion of the energy of each , and so gives a measure of how important each mode is to the macrostructure derived from f1. Finally, we define the map alignment statistic to be the sum of the , weighted by the contribution of to the large-scale organization of f1:
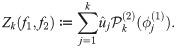
Here we briefly discuss how to choose k so that Zk gives an accurate measure of the degree to which Φ(1) is determined by . Recall that the head of the spectrum of is sensitive to large-scale changes, but the bulk of the spectrum is associated to high frequency eigenfunctions, capturing small-scale organization often attributable to noise or local idiosyncrasies in the data. As a result, given training data or simulated data one may simply estimate a value of k after which the variance explained by the eigenspace, , is approximately independent of the macrostate of the system. That is, choose k so that for j > k, the value λj makes up a fixed fraction of the sum of the eigenvalues.
Alternatively, in using empirical data we found the bulk of the spectrum often follows an approximate power-law decay. As a result, one may take k to be the smallest integer such that for j > k, λj ≈ Cj−β for positive constants C, β.
These are necessarily rough guidelines, and in practice one often finds a range of plausible choices for k. However, when increasing k the additional summands of must eventually become essentially independent () of the leading elements of . It follows that after a point, a larger value of k has little influence on the computed MAS, Zk(f1, f2). Therefore an overestimate of k has very little effect on the results, so it is advised that in practice one err on the side of larger choices of k.
If the system under study exhibits multiple emergent behaviors relating the two variables f1 and f2, then coherence alone is not enough to identify system behavior. In passing to the norm of the vector , we clearly give up a significant amount of information. In order to distinguish multiple coherent states, we inspect the individual dot products that comprise the map alignment statistic.
However, to remove the effects of the trailing diffusion coordinates, which correspond to smaller scale variations in the geometry of , we consider the sequence of inner products given by
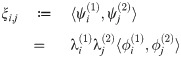
While the diffusion coordinates provide a natural organization of the data, the individual components of the map are eigenvectors, and so are computed via an iterated maximization problem: given the linear operator A, the ith eigenvector is given by
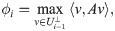
Therefore, for each collection {ξi,j: 1 ≤ i, j ≤ k} we define the map σ: [k] × [k] → [k2] so that the components of (|ξσ(i, j)|) are ordered by decreasing magnitude. (Here [k] denotes the first k positive integers). This removes the ambiguity in both index and sign for these products. We call the resulting vector the f1 f2-covariance vector (at time t), abbreviated as ξ (resp. ξ(t)). One may then use these vectors as a fingerprint for the macro-scale relationship exhibited between f1 and f2 at a given time.
Fig 3, panel A, gives an example of a toy flocking system comprised of 50 agents, exhibiting a circling behavior at time t1 and a (mostly) aligned state at time t2; its top four diffusion coordinates associated to both Φ(1) and Φ(2) are displayed for each time. (The choice of affinities and here are the same as in the flocking model below, being based on spatial proximity and velocity, respectively). In panel B we see the absolute values of the inner products of the diffusion coordinates, where the matrix (represented by a color plot) has its (i, j)-entry given by . Finally, in panel C we see the covariance vectors at times t1 and t2.
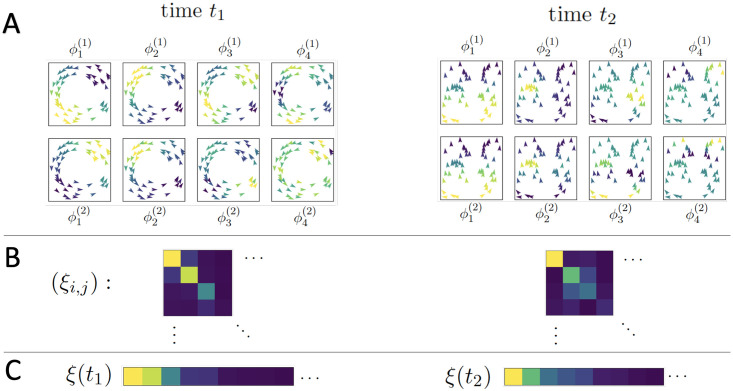
A toy system of 50 agents; the left and right sides of the figure represent observations of the system at two different times when the system is in two different organized states.
(A) Agents in each subpanel are colored by the indicated diffusion coordinate, (B) A color plot of the matrix (ξi,j) with yellow indicating larger values, blue indicating smaller values, (C) The values of the above inner product matrix, ordered by absolute magnitude; these are the vectors used to classify the system’s regimes.
Covariance vectors allow us to embed the activity of the agents in a shared space, , and perform clustering analyses to group similar macro-scale relationships between f1 and f2 over time. In the next section we will perform a boilerplate clustering analysis to distinguish between distinct coherent group structures found in a data set of golden shiner schooling behavior, a task for which the map alignment statistic is insufficient on its own.
As a first test of our method we explored a well studied agent-based model of flocking behavior [28] (see S2 and S3 Movies for a visual reference). The model consists of a set of N agents, {xj}, moving on the torus T1 = S1 × S1, each with position pi and velocity determined by the angle θi and the magnitude vi. In this model each agent moves with a fixed speed, vi = vj for all i and j, so we simply write v for this speed.
Each agent’s direction is updated at each time step by the average local direction plus a noise term, a normal random variable distributed as N(0, ϵ2). Here local refers to the agents within a certain distance r of the focal agent. With all other parameters of the model fixed, the coupling parameter r governs the degree to which the system self-organizes. In the hydrodynamic limit, long-range order emerges for r above some critical value rc(v, ϵ) > 0, meaning that the mean velocity of the flock is nonzero: . The direction of group travel is chosen randomly, and breaks the symmetry of the system. See S1 Text for model details.
In the discrete time, finite-agent setting we observe the mean velocity of the flock, 〈vj〉 = (v cos〈θj〉, v sin〈θj〉), taking this as our ‘ground truth’ measurement of the level of emergent, coherent behavior in the system. As r increases past rc(v, ϵ), the mean velocity (in the large N limit) transitions from zero to a nonzero value. However, this shift occurs continuously; as r grows we find the steady-state mean velocity of the flock increases towards its maximum value. Even with r = 0 the global mean velocity will have magnitude and suffer fluctuations, so determining whether a preferred flock-wide direction of motion has been chosen in the finite case makes little sense. Instead, below we compare the value of Zk(p, v) to 〈vj〉 to determine how well the MAS detects large-scale organization.
We chose two metrics to define a pair of time-evolving graphs as follows: Since we are interested in flocking behavior, we let d(1)(xi, xj; t) be the euclidean distance between the and agents at time t, while d(2)(xi, xj; t) denotes the kernel-smoothed L2 norm of the two agents’ relative speed profiles. (See (S3), (S4) and (S5) for the explicit definitions of the metrics used). In particular, d(1) captures the spatial information in the flock, while d(2) measures the degree that agents are moving in concert over a short (on the order of 10 time steps) recent period.
We then applied diffusion maps to the resulting sequence of graphs and calculated the map alignment between the two variables, p and v. The choice of subspace size to use, k = 10, was empirical. We observe that at various levels of organization the variance explained by the first five modes (i.e. the sum of the magnitudes of the first four components of ) is highly variable, while the variance explained by the higher modes () shows little dependence on system organization, though we decided to increase k to 10 to be conservative. This suggests that the macro-scale information is well captured by , while components 11 through 500 are largely accounting for noise and small-scale features of . Note, however, that one may take k larger than 50 without any qualitative change in the analysis.
In Fig 4 below we plot the map alignment statistic Z10(p, v) (blue) calculated from two sets of 100 independent simulations of the flocking model with 500 agents and fixed parameters (ϵ = π/5, v = 1/320, see SI). In the left panels the coupling parameter r is held at a low value (r = r0 = 0.0065) for 800 time steps before increasing linearly to a high value over 400 steps and remaining at that value (r = r1 = 0.06) for the rest of the trial; see the lower panel of Fig 4A. The mean velocity 〈vj〉 of the flock, averaged over the 100 trials, is plotted in orange in the upper panel.
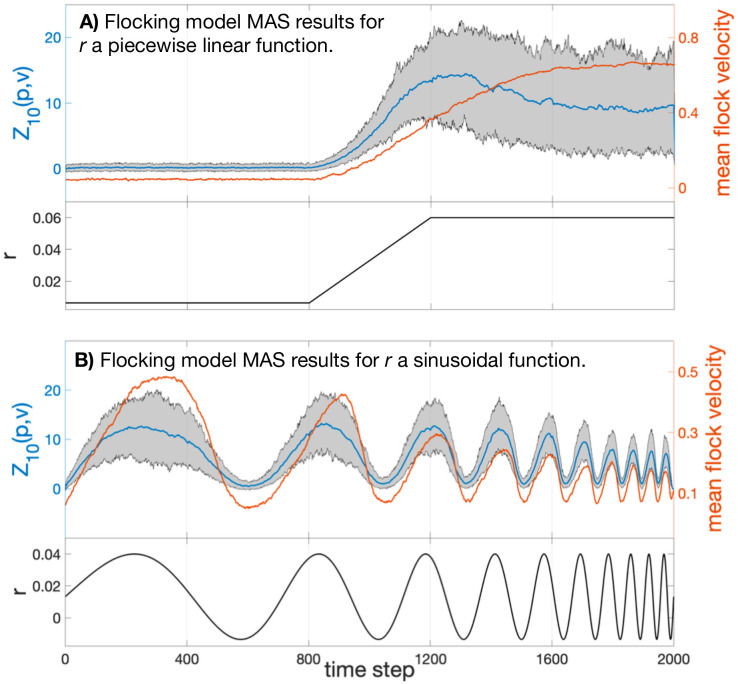
Top: Map alignment statistic Z10(p, v) averaged over 100 flocking simulations of 2000 time steps (blue). The grey region denotes the 90% empirical confidence interval of Z10(p, v). The mean velocity 〈vj〉 of the flock is averaged over the 100 trials and plotted in orange. Bottom: The model’s coupling constant r plotted over time. Notice that in (B) the MAS does not suffer the same hysteresis that the flock’s speed does.
One can see that the statistic Z10(p, v), measuring the dependence of position diffusion coordinates on the velocity diffusion coordinate system, has a strong correspondence with the velocity correlation statistic. That is, large-scale organization was clearly detected and quantified using only the two micro-scale inter-agent distance time series.
In a second trial we explored how quickly map alignment and long-range correlations vary in response to change in the micro-scale dynamics of the agents. This is done by allowing r to vary sinusoidally between r0 and r1, with increasing frequency. The black line plotted in the lower panel of Fig 4B shows the coupling parameter as a function of time; in the upper panel the orange line shows the magnitude of the mean velocity of the flock, and the blue plot gives the mean value of Z10 across trials, with the filled area indicating the 90% confidence interval for Z10.
Clearly Z10(p, v) indicates strongly the presence or absence of correlation. The map alignment statistic shows both a faster response to changing r and suffers from less attenuation as the speed of parameter change increases. Times t = 800 to 1000 especially highlight how the drop in Z10 is a precursor to the value of the macrovariable 〈vj〉 falling. In this case and the previous case, we find we are able to track the transition from unorganized motion to flocking by the alignment between the velocity diffusion coordinates, , and the position diffusion coordinates, .
As an empirical application we use position and velocity data for a school of golden shiners (notemigonus crysoleucas); details of how the data were collected can be found in S1 Text (see also S1 Movie for a visual reference to these data). These fish were studied in [29, 30]. In [30] the authors found that the school, constrained to an essentially two dimensional environment, would generally be found in one of three macro-states defined according to the school’s collective polarization, Op, and rotation, Or: milling (circling), swarming (disordered, stationary), or polarized (translational). See S1 Fig for example frames of these behaviors. Writing v(xi) for the velocity of fish i and p(xi) for its position, the chosen macrovariables are defined as
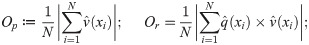
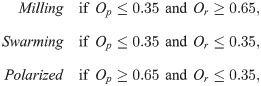
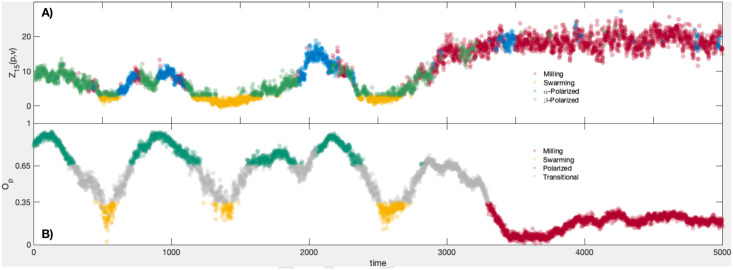
Statistics calculated from 5000 frames of the golden shiner dataset.
A): Map alignment Z15(p, v) calculated over 5000 video frames. The plots are colored according to our classification of macro-scale state; milling = red, swarming = yellow, α-polarized = blue, β-polarized = green. B): The group polarization macro-variable Op calculated from the same 5000 frames. The coloring shows the states according to [29]; milling = red, swarming = yellow, polarized = teal, unclassified/transitional = grey.
For the study of fish schooling, as with the simulated data above, we built a pair of distance matrices at each time step. The first was calculated from the euclidean distances between agents (individual fish), d(1), defined as before. The second, d(2), using the velocity data only. In this case, our goal was to capture any interaction between agents, either instantaneous or at a time lag due to one fish leading another. Therefore we define d(2)(xi, xj;t) as in the previous section (a weighted L2 norm of the differences in the agents’ recent velocity profile), but now allow one of the two agent’s velocity profiles to begin up to two seconds earlier. This amounts to starting the trajectory at an earlier time step, t − ℓ, with 0 ≤ ℓ ≤ 60. We take d(2)(xi, xj; t) to be the minimum of this collection of distances, as this choice of time translation gives the best alignment of the two fishes’ trajectories.
As with the flocking model, the first diffusion map’s leading coordinates identify the large groups of fish who form spatially proximate clusters; the leading diffusion coordinates associated to d(2) highlight groups whose velocity profiles are (up to a 2s, or 60 frame, translation in time) quite similar. The map alignment between these two systems, Z15(p, v), is plotted in the upper panel of Fig 5. When the fish are swarming (see S1 Fig, center column) we see that these two coordinate systems are unrelated, and that Z15(p, v) is correspondingly low.
Here again, the choice of k = 15 is driven by observing that outside of the top fifteen entries of for , i ∈ {1, 2}, the spectral decay appears to follow a power law for most frames (though this observation does break down for some frames when the eigenvalues become small enough). The results below prove to be robust to varying k from 10 to 25. Therefore the span of contains the majority of the structure within the data, while k = 15 is not so large that the signal in Zk becomes diluted.
The two coherent behaviors we would like to separate are the polarized, or linear, motion (right column in S1 Fig) and milling, or circling, motion (left column in S1 Fig). Both states exhibit high levels of organization, and we must use a sharper tool to distinguish them.
To do this we employ the covariance vectors ξi,j, as defined in the Unsupervised Macrostate Classification section above, over the course of 5000 frames of video. First, those states with Z15(x, v) < 3 are considered to exhibit incoherent behavior and to have no macro-scale dynamic, so we classify them as swarming frames and remove them from the set of frames to be classified. (NB: the summands for 1 ≤ j ≤ 15 are centered, unit variance random variables if we assume the two coordinate systems are unrelated. For this reason the threshold of 3 can be considered a reasonably large deviation from the mean for Z15(x, v). However, the choice is ad hoc, and users may modify this threshold in practice if it enables them to better subdivide their system into different behavioral regimes). Then for each time t we compute the covariance vector ξ(t) = (|ξσ(i,j)(t)|). We cluster the resulting vectors using the k-means algorithm, with k = 3. This leaves us with three groups representing distinct coherent behaviors, labelled G1, G2, and G3, as well as the incoherent group, which we label N. These groups define the coloration of the top panel of Fig 5. Comparing these group memberships to those given by calculating the group polarization and rotation, Op and Or, and classifying behavior as in [29] we find that group G1 contains 85.86% of the milling frames, G2 and G3 together comprise 87.47% of the polarized frames, while N holds 65.85% of the swarming frames (another 32.01% are relegated to G2). The full results of the classification appear in Table 2.
| Milling | Swarming | Polarized | Transitional | |
|---|---|---|---|---|
| G1 | 1463 | 5 | 73 | 348 |
| (85.9%) | (1.5%) | (5.1%) | (22.5%) | |
| G2 | 0 | 105 | 738 | 454 |
| (0%) | (32.0%) | (51.9%) | (29.4%) | |
| G3 | 241 | 2 | 505 | 352 |
| (14.1%) | (0.6%) | (35.5%) | (22.8%) | |
| N | 0 | 216 | 105 | 391 |
| (0%) | (65.9%) | (7.4%) | (25.3%) |
That the polarized frames are divided into two separate clusters suggests that there are two distinct modes of polarized behavior exhibited by the fish. Upon inspecting ξ(t) for the frames from each cluster, we find that the two groups are essentially distinguished by their relative levels of organization; for example, the mean value of Z15 for cluster G2 was 6.3186, while for G3 the mean map alignment statistic is 12.0878. Practically, the frames of cluster G2 typically consist of polarized group motion with multiple subgroups of fish following distinct paths; we call this β-polarized behavior. This creates a macro-scale division in the network structure of that is not present in the network structure of , which leads to a lower alignment between their top eigenvectors; here 〈ξ1,1(t)〉 = 0.176. On the other hand, the frames of G3 feature a single, unified group motion, leading to a high alignment (〈ξ1,1(t)〉 = 0.331) between the top diffusion coordinates of each network. We refer to this as α-polarized schooling behavior. It is possible that there is a correspondence between the empirically defined β-polarized activity and the dynamic parallel group behavior described in the family of models of [31].
One may approach the problem of classifying the covariance vectors {ξ(t)} in numerous ways; we chose the k-means algorithm for its simplicity. However, it requires the user to fix the number of desired clusters beforehand. As the prior work of [29] only defined two separate coherent behaviors, milling and polarized, one may wonder what results we would find if we instead restricted the classification to two clusters. We did this and, labelling the groups G1* and G2*, found that G1* successfully captures all the milling frames, and G2* is predominantly composed of polarized frames (see S1 Table). However, roughly 1 in 4 polarized frames are relegated to G1*. S2 Table shows how the two k-means clusterings apportion the frames. In particular, the α-polarized frames tend to be classified as milling. By increasing the number of subgroups to k = 3, we allow the algorithm to perform a more sensitive clustering, which improved the correlation between our groupings and those of [29], as well as distinguished between two forms of polarized behavior that were grouped together in that work. (Note that while one could increase the number of clusters k to four or five, one experiences diminishing returns in the sense that the differences in schooling behavior will become increasingly subtle).
To identify different states of collective behavior in complex systems, we have developed and applied a new methodology based on measuring changes in the mutual geometry of a given system as it is viewed through different lenses, using diffusion maps. The method is general and objectively produces system-specific, macro-scale variables, Zk and ξ for tracking the onset of and distinguishing between different regimes of collective behavior. To test the method, we applied it to synthetic data produced from a well-known model of birds flocking, and to empirical data on fish schooling. In both cases the macro-scale quantities constructed using diffusion maps provided an accurate description of the system in terms of the degree and type of collective behavior present.
The analysis, while data-driven, does suggest methods of controlling complex systems, or nudging them towards a desired state, as in [32]. For example, the top panel of Fig 5 suggests that swarming behavior is typically bookended by a β-polarized state. Then to bring the school into a swarming state from an α-polarized state, one might attempt to force the fish to break into multiple polarized subgroups (by instituting an obstruction, say). Achieving a misalignment of the leading diffusion coordinates from the spatial- and velocity-based networks of the school will clearly impede any group consensus, making the school more likely to lose its coherence. This strategy is surely obvious in the case of schooling fish, but an analogous tactic could be employed to inform control over state change in markets or social networks as well.
Furthermore, the diffusion coordinates provide a quantitative basis for choosing how to align/misalign a system; one can use in silico experiments to identify changes to the network structure which would move the system towards the desired macro-state. Given a target covariance vector, the technique could perhaps be automated. One approach would be to perform spectral clustering of the network according to the present and target eigenfunctions. Agents belonging to the same cluster in both cases could be expected to remain well-connected during the transformation, simplifying the search for an appropriate perturbation to those that only increase/decrease the connectivity of those clusters. Reducing the problem space in this way would be a first step towards an online solution, advising system control in real time.
Flocking models and empirical data on fish schooling were studied here because the collective behavior from each system is well known. That is, the scales at which collective behavior emerges and the macro-scale variables that do a good job of describing group behavior are known. This allowed for a clear demonstration of the new methodology, though one can apply this framework to a variety of dynamic or static data sets, from subfields outside animal group dynamics, and areas other than biology. There are many non-biological systems, such as financial and housing markets, city-transit systems, and power-grid systems, which are known to exhibit emergent patterns at a range of scales, but for which the relevant micro-scale variables are less well known. In these cases one may compute map alignment in an uninformed fashion, testing a variety of metrics and variables, to discover latent emergent relationships.
In practice, the decision of which micro-scale metric to use may not always be clear, but the map alignment method offers a resilience to these particulars. In the two cases studied, familiarity with animal collectives and their emergent properties made the choice to use position and velocity data snippets and their respective metrics a straightforward decision. However, there are many other biological systems where the organizational variables to choose may not be so obvious [33]. While the exact variables controlling information propagation in such systems may be unknown, as demonstrated in [34], the underlying structure may still be recovered through measurements of different, related variables. That is, we take advantage of the gauge-invariance of the diffusion map approach. As many previous publications have pointed out [29, 35, 36], fish do not interact with one another based purely on their euclidean distance; other factors including rank of nearness (closest neighbors), relative alignment, and density. Therefore the metric d(1) used above is a gross simplification of the role spatial organization plays. However, it captures enough of the true underlying organizational structure to allow us to detect emergent behavior.
It is worth noting, however, that the approach that we have developed has its own challenges relating to the nature of the data used. Diffusion maps inherently require a large number of data points for the diffusion operator to exhibit the regularity of the limiting operator on the manifold from which the data is, in theory, sampled. With the fish data though, the intermittent nature of the observations meant that the system size n varied between roughly 70 and 280 agents, and still the method proved resilient to these fluctuations.
Also, if one employs the GkNN kernel as we do here (see (1)) the scale-free property simplifies the task of resolving the macro-scale structure of the data; in particular, one does not need to adjust the kernel if the distances involved globally grow or shrink. But this entails a loss of information. As an example, if the system becomes highly organized when observed via the metric d (e.g. d corresponds to the velocity-based metric d(2) above, and the fish all move as one) the corresponding data cloud (X, d) collapses towards a point mass. However, the GkNN kernel rescales distances in order to resolve their structure across scales, i.e. the rescaled distances only have meaning by virtue of their relative size. As a result the network’s features can become a measurement of the lower-order stochastic fluctuations of individual agents’ trajectories, rather than meaningful organization. This conflation of extremely organized and unorganized states could be overcome by tracking the mean inter-agent distance, for example, and may be important in application.
Measuring the map alignment between different networks induced by separate metrics on a graph serves as an entry point for several other possible analyses. One could use a set of training data to perform a classification of the various emergent behaviors of the system, then measure the stability of the system (risk of state change) by the current distance from ξ(t) to representative subgroups from the various states. For example, if the distance from ξ(t) to Group 1 is growing, and the distance to Group 2 is shrinking, one might anticipate a shift in macrostate. In this way one may estimate the risk of emergence, dissolution, or a large-scale shift of collective behavior. The authors believe, based on preliminary analysis of the fish schooling data, that such an approach could provide a new early warning metric for complex systems whose relevant macrovariables may be unknown, inhibiting the application of other early warning signals such as critical slowing down.
The method that we have developed is a new data-driven approach for detecting cross-scale emergent behavior in complex systems. It quantifies the dependence present between various micro-scale variables (those exhibited at the agent-level), and formulates a signature of the macro-scale behavior exhibited by the collective. The method can also detect the onset or loss of organization in an unsupervised fashion. With sensible choices of micro-scale variables, which are now measured routinely as Big Data, any complex system can be studied in this way. Doing so presents new opportunities for studying complex systems through analyzing their changing geometry.
The authors would like to acknowledge Kolbjørn Tunstrøm for providing the fish schooling data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
 Unsupervised manifold learning of collective behavior
Unsupervised manifold learning of collective behavior
 Facebook
Facebook
 Twitter
Twitter
 Linkedin
Linkedin
 Whatsapp
Whatsapp

