 dadi.CUDA: Accelerating Population Genetics Inference with Graphics Processing Units
dadi.CUDA: Accelerating Population Genetics Inference with Graphics Processing Units
Molecular Biology and Evolution


- Altmetric
dadi is a popular but computationally intensive program for inferring models of demographic history and natural selection from population genetic data. I show that running dadi on a Graphics Processing Unit can dramatically speed computation compared with the CPU implementation, with minimal user burden. Motivated by this speed increase, I also extended dadi to four- and five-population models. This functionality is available in dadi version 2.1.0, https://bitbucket.org/gutenkunstlab/dadi/.
Population genetic data contain information about the history of the sampled populations, but extracting that information often demands computationally expensive modeling. dadi is widely used for inferring models of demographic history (Gutenkunst et al. 2009) and natural selection (Kim et al. 2017) from data summarized by an allele frequency spectrum (AFS). The user specifies a model with parameters for population sizes, migration rates, divergence times, and/or selection coefficients. Given a set of parameters, dadi computes the expected AFS and the composite likelihood of the data. The parameters are optimized to maximize that likelihood, and AFS computation dominates optimization run time. Here, I show that Graphics Processing Units (GPUs) can massively speed AFS computation and thus overall inference.
GPUs have rarely been applied to population genetic simulation or inference. Lawrie (2017) developed a GPU implementation of the single-locus Wright–Fisher model, finding speedups of over 250 times compared with a CPU implementation. Zhou et al. (2015) implemented a subset of the IM program for inferring demographic models (Hey and Nielsen 2004) on a GPU, finding speedups of around 50 times.
For dadi, the core computations are solving a partial differential equation (PDE) for the population distribution of allele frequencies and integrating over that distribution to compute the AFS. Solving the PDE reduces to solving a large number of tridiagonal linear systems (fig. 1A). To solve these systems on the GPU, I used the Valero-Lara et al. (2018) algorithm, as implemented in the Nvidia Compute Unified Device Architecture (CUDA) library. dadi is primarily written in Python; to interface with CUDA I used the PyCUDA (Klöckner et al. 2012) and scikit-cuda (Givon et al. 2019) libraries. Computing the AFS from reduces to matrix multiplication, which did not consistently benefit from a GPU, so this step remains on the CPU.

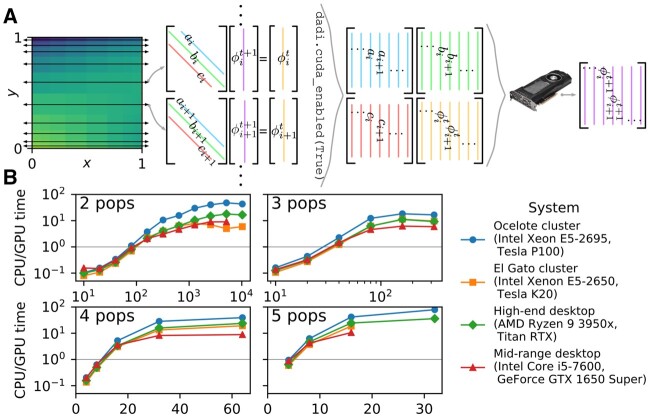
(A) Illustration of dadi integration. During each timestep, the population allele density is updated for each population axis. Each row and column over which is approximated yields a tridiagonal linear system. In the GPU implementation, these systems are solved in parallel. (B) Ratios of CPU to GPU times to compute the AFS for several models on several computing systems, versus AFS size. Absolute computation times are shown in supplementary figure S1, Supplementary Material online. The largest AFS size tested on each system was constrained by GPU memory.
For the end user, dadi GPU usage requires only a single call to dadi.cuda_enabled(True).
I evaluated performance by comparing times to compute the AFS for models from stdpopsim (Adrion et al. 2020) on several computing systems. To achieve reasonable accuracy, for spectra with n chromosomes per population, I used extrapolation grid points of (⌊1.1n⌋ + 2, ⌊1.2n⌋ + 4, ⌊1.3n⌋ + 6). The benchmarking code is available in the dadi source distribution.
Historically, dadi is most often used with two- or three-population models. I thus tested the two-population model of Li and Stephan (2006) and the three-population model of Gutenkunst et al. (2009). Using a GPU was beneficial if the sample size was greater than 70 for two populations and 30 for three populations (fig. 1B and supplementary fig. S1, Supplementary Material online); such values are common in data analyses.
Given the GPU speedup, I extended dadi to four- and five-population models. Tests with the four-population New World model from Gutenkunst et al. (2009) and the five-population archaic admixture model from Ragsdale and Gravel (2019) again showed substantial GPU benefits (fig. 1B and supplementary fig. S1, Supplementary Material online). Models with more populations typically have more free parameters, which increases the expected number of optimization steps. So optimizing the parameters of four- and five-population models may be challenging even with GPU acceleration.
The ultimate benefit of GPU computing is high performance at low cost. At time of writing, the consumer GeForce GPU costs less than $200, but it substantially speeds computation. The data center Tesla P100 costs roughly $6,000, and it can be used to calculate larger spectra because of its larger memory. The Valero-Lara et al. (2018) algorithm is typically bound not by computation, but rather by memory bandwidth within the GPU. Compared with consumer GPUs, data center GPUs typically have a large advantage in double-precision computation but a more modest advantage in memory bandwidth. So for dadi usage, consumer GPUs may provide better performance versus cost.
The GPU speed improvements increase dadi’s competitiveness with other methods for calculating the expected AFS, such as moments (Jouganous et al. 2017). The speed differences between the GPU and CPU implementations of dadi are larger than the differences between the CPU implementations of dadi and moments, in both present (supplementary fig. S2, Supplementary Material online) and previous (Jouganous et al. 2017) benchmarks. Other factors may influence choice between these methods, including level of support and access to more advanced features, such linkage disequilibrium statistics in moments (Ragsdale and Gravel 2019) or distributions of fitness effects in dadi (Kim et al. 2017).
Acknowledgments
This work was supported by the National Institute of General Medical Sciences of the National Institutes of Health (R01GM127348 to R.N.G.). This material is based upon High-Performance Computing resources supported by the University of Arizona TRIF, UITS, and Research, Innovation, and Impact (RII) and maintained by the UArizona Research Technologies department. I thank Xin Huang for benchmarking assistance and Andreas Klöckner for guidance to the Python CUDA ecosystem.